


Let’s dive into the topic, whether computer can help us predict emotions hidden in text. While reading an article, one can easily extract statistical data, such as word count or sentence length. What about problems more subtle and complex problems? That’s where sentiment analysis come across with its typical NLP task.
We can approach the problem from various perspectives. Firstly we can create a machine learning model, train it on our data and test how well it copes with new examples. Other perspective is to create a lexical sentence analysis. While English has many rich ready to use tools, Polish language is far less global. Moreover lexical analysis is less researched than machine learning models. We decided to check how well does this approach make out with sentiment analysis.

We can divide lexical analysis into some steps. We need our articles being divided into sentences, and sentences into tokens – single words in general. That’s why we cleaned up text from unnecessary characters and abbreviations. Then we focused on lemmatisation, meaning process of extracting word’s canonical form or dictionary form. It will allow us to reduce word collection only to lemmas. We used a tool stanfordNLP – useful to recognize part of speech and word’s lemma.
Next we could attribute all words with their sentiment value. We use LOBI word set which is a collection of 3k words and it’s sentiment.
After all preprocessing we could dive into the essence of analysis. We use Spacy tool for Polish language to create a dependency tree. Let’s see how well it operates on a sentence “The sun was shining, and there was a light wind”.
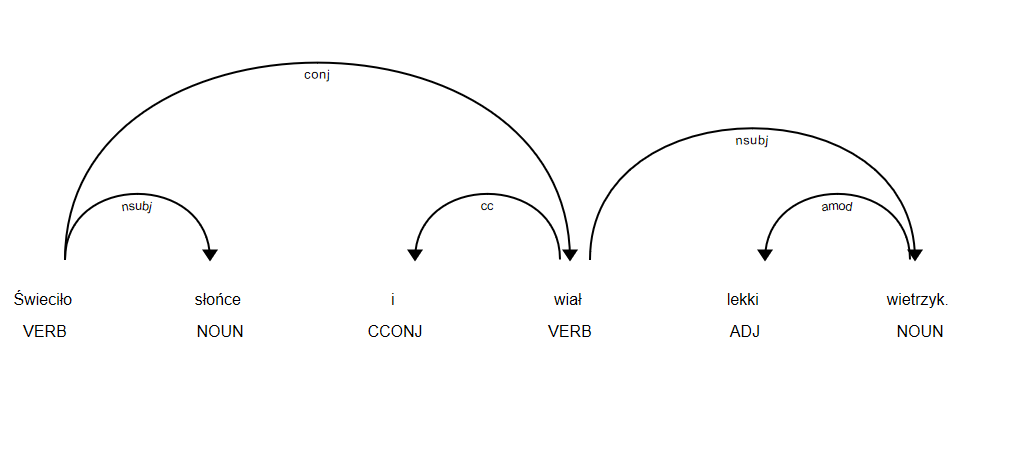
But wait – what is the point of Dependency Parsing while we could just count positive and negative words in sentence? For simple sentence it is just enough, but for complex ones ex. “John have helped poor people, but in fact he is a thief” the result would be far from expected. That’s why we divided complex sentences into component parts, using Universal Dependencies tag set. All particles were attached with suitable sentiment value. We need to gather rules how to compare sentences properly. Let’s see an example sentence “Ann had many friends, however she was lonely”. The conj – conjunct tag is the one to divide sentence into logical parts.
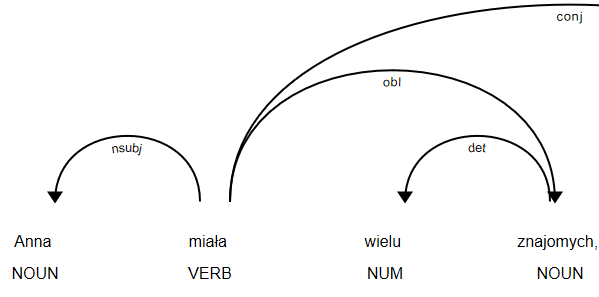
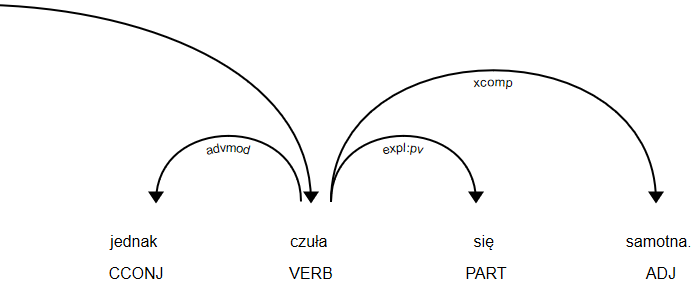
Then we compute sentiment of compound sentence, for the first part it is positive, while for second – negative. How to say what is total sentiment? We check what conjunct connects two compounds, “however” in this case. It means second compound is more important, that’s why we would assign the sentence with negative sentiment.
Eventually we tested how well does the algorithm work with larger datasets. We gathered sample of labeled data – positive, neutral, negative and mixed sentiment from books, politician transcripts and reviews.
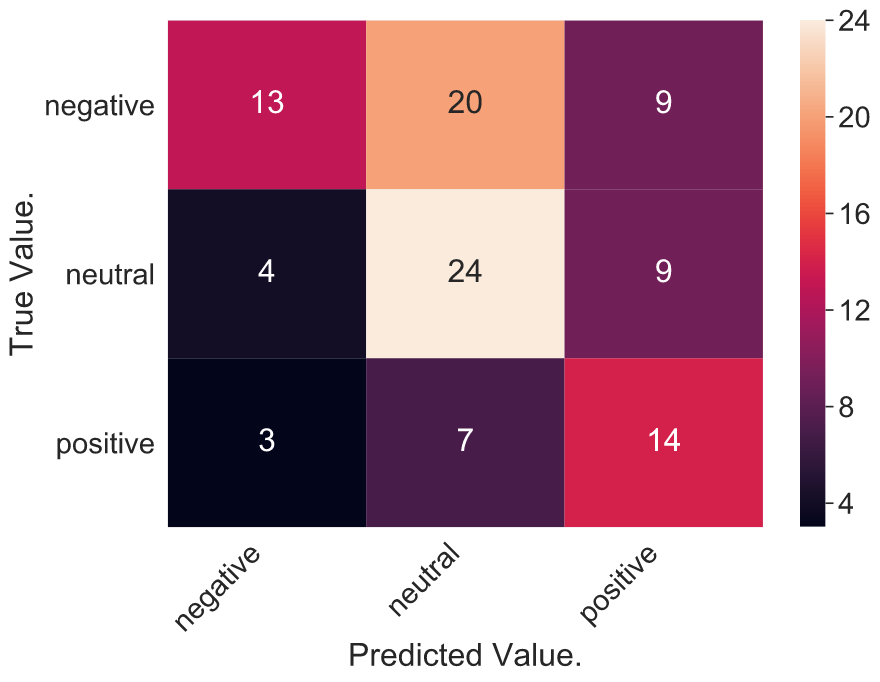
We can see in many cases sentences were wrongly assigned as negative while they were neutral. It is because dataset is ill-balanced.
Lastly we can consider other examples of sentences, that does not fit to our model, and leave a space for it’s development. For instance while having a sentence: “Ann is not intelligent, but Mark is fabulous. ” it is hard to say whether it is positive or negative. We would rather say it has got mixed sentiment and compounds should be treated separately.
Summary
To sum up, this articles shows how to systematize emotions and sentiment in text. Starting with clean-up and lemmatization until complex sentence division and rule classification. It is worth mentioning, well-balanced sentiment word set could optimize effectiveness of an algorithm. Please note, this is only one approach and does not exhaust the whole topic.


