


As the number of machine learning projects grows, Machine Learning Operations (MLOps) becomes a crucial element in managing the full lifecycle of machine learning models. This includes data collection, training, evaluation, deployment, monitoring, and updating models. Many current MLOps solutions focus on managing individual models or small collections of models that can be manually defined. But what happens when a single model is not enough, and a complex system requires multiple models working on different datasets? For example, in the context of sales analysis or forecasting for different regions or customer segments, each might require its own specialized model. How can we effectively manage and monitor dozens or even hundreds of similar models in an automated and scalable way? How do we ensure that adding new models and pipelines is quick and seamless? In this article, I will explain how we tackled this challenge, describe our architecture, and discuss the difficulties we encountered.
Project Introduction
The project was developed for a client integrating online stores with various marketplace platforms, such as Allegro, eBay, and Amazon. The goal was to create a system that automatically classifies products into the correct categories on these platforms, based on the product name entered by the user. The main challenge was to build a text classification model that could handle assigning products to the thousands of categories available on each platform.
Challenges
- Large number of classes: For example, Allegro offers 13,788 product categories.
- Data requirements: To ensure model efficiency, we need at least 2,000 product names for each category.
- Dynamic category tree: Product categories on marketplaces often change, requiring continuous data updates.
- Limited data access: Many stores do not provide data in an easily accessible way.
- Scalability: The need to support multiple stores requires a flexible and easy-to-manage solution.
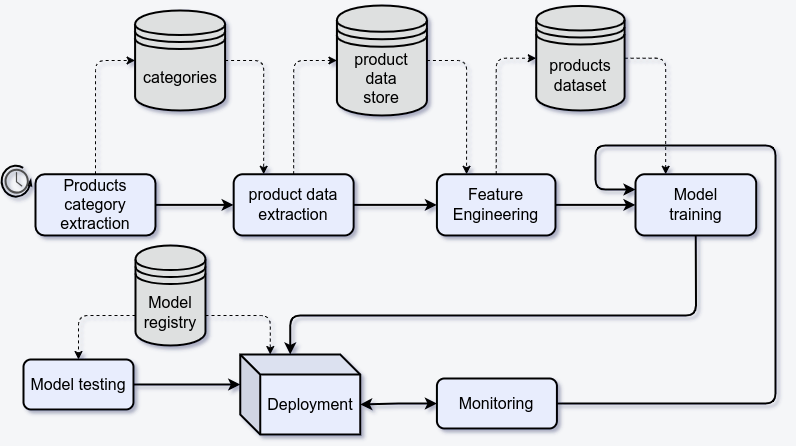
Model Orchestration Architecture
The system architecture consists of several modules that are commonly found in MLOps projects:
- Data acquisition
- Data preparation
- Model training
- Deployment
- Monitoring
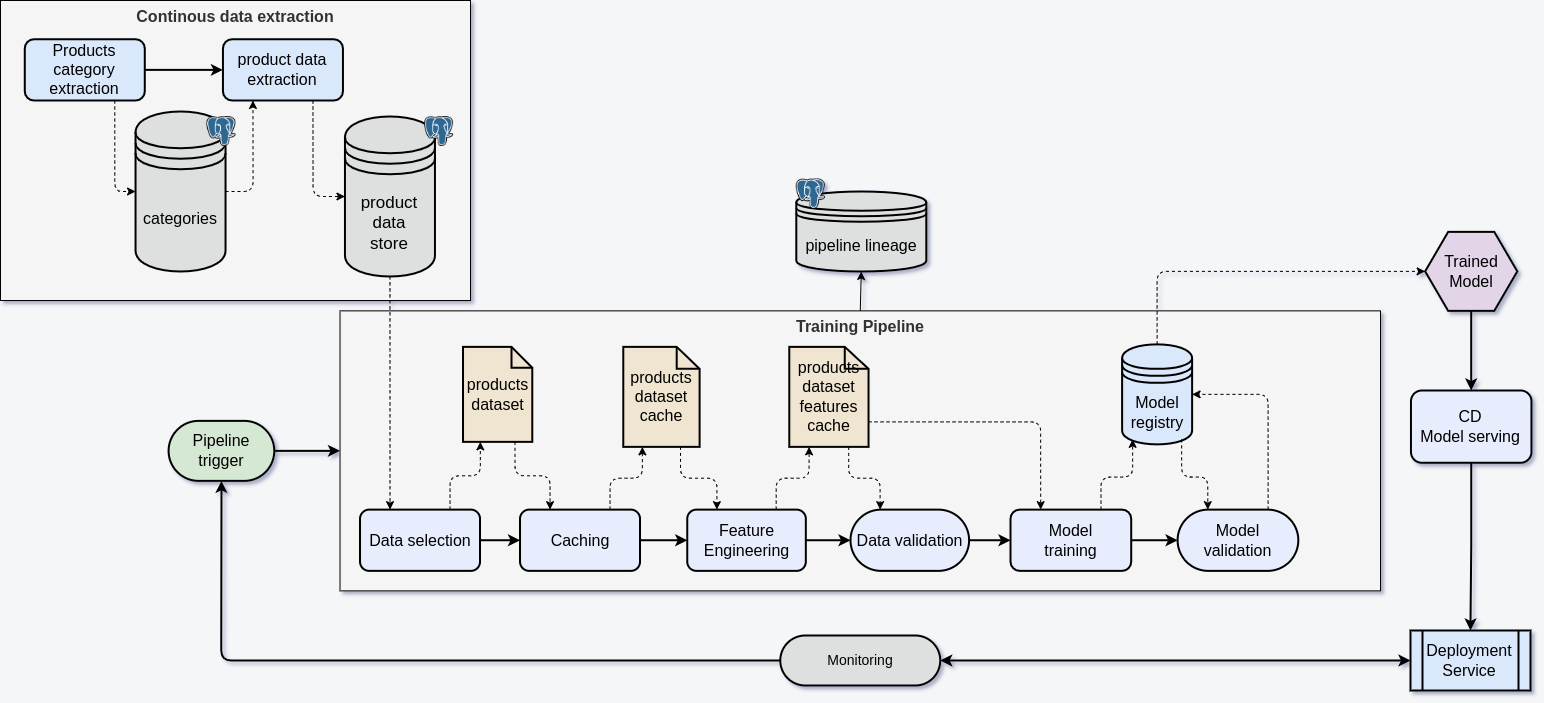
Data Acquisition
We begin the data acquisition process by establishing the category tree structure for each store. With this regularly updated tree, we can monitor the progress of data collection and track the dates of the most recent updates for each category. To ensure sufficient data for model training, we collect at least 2,000 products assigned to each category.
Data Preparation
In our project, the training data did not require extensive processing. The pipeline focuses on creating a training dataset and precomputing vector representations of product names, which speeds up the model training process by eliminating the need to recompute these vectors during training.
Containerization
Containerization plays a key role in the entire pipeline. We split tasks into smaller ones, which are run on Airflow workers using PythonOperator, and larger tasks, such as data acquisition and model training, which are run as Docker containers using DockerOperator.
Benefits of Containerization
- Environment isolation: Each task has its own dependencies, eliminating compatibility issues.
- Ease of deployment: Containers can be run on different machines, including those equipped with GPUs.
- Updates: Containers are automatically built in the CI (Continuous Integration) process, and the latest versions are pulled when running in Airflow.
Dynamic Pipeline Creation
The pipeline for a single marketplace is ready, but pipeline creation for each new store must be automated to avoid manual configuration. This becomes important as the number of stores grows to dozens or even hundreds.
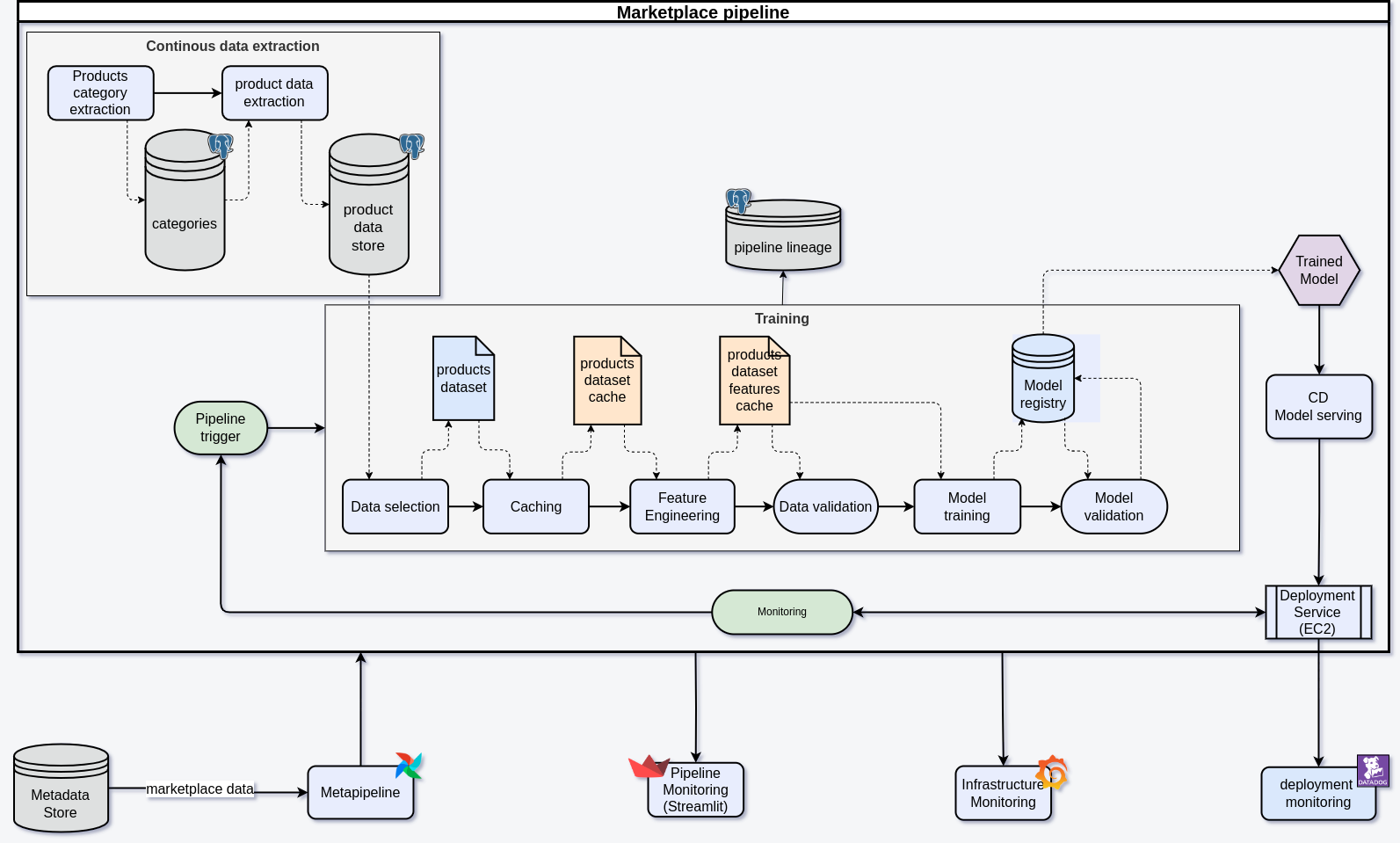
Pipeline Configuration
We store pipeline configurations in the MLFlow registry. Specific settings for each store, such as data sources or database schemas, are generated dynamically. For example, the configuration for Amazon includes details about data sources, commands for downloading products and categories, and a schedule for updates.
After adding such a configuration, the pipeline is automatically created and operates according to the defined parameters.

Continuous Data Acquisition
Each store requires a dedicated crawler or API script for product retrieval. Full automation of this process is not possible, but shared libraries can facilitate integration with the database. Crawlers must be reliable and scalable. To avoid long-running tasks, a crawler can be stoppedpaused and resumed without losing progress. Every six hours, the crawling task is reset, allowing for regular updates and better log management.
Database Management
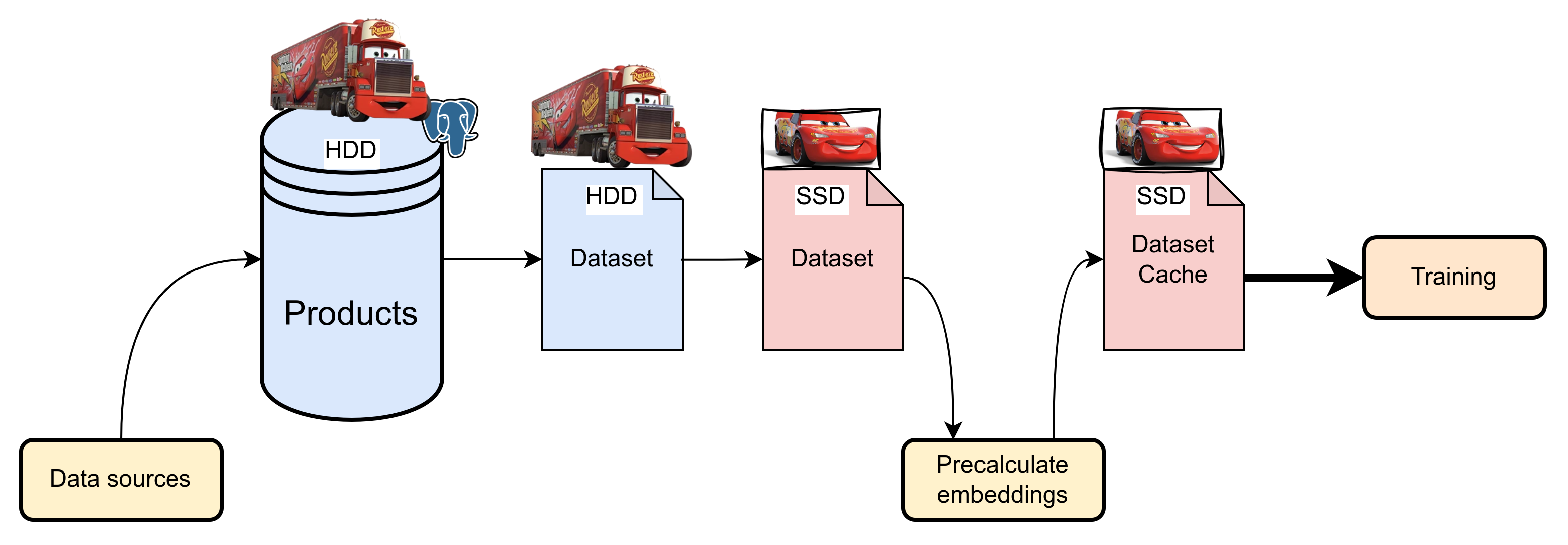
Effective management of large datasets is critical for system performance. Initially, we used fast SSDs for storing and processing data, which worked well despite frequent table join operations. However, as data volumes grew, the cost of SSDs became significant.
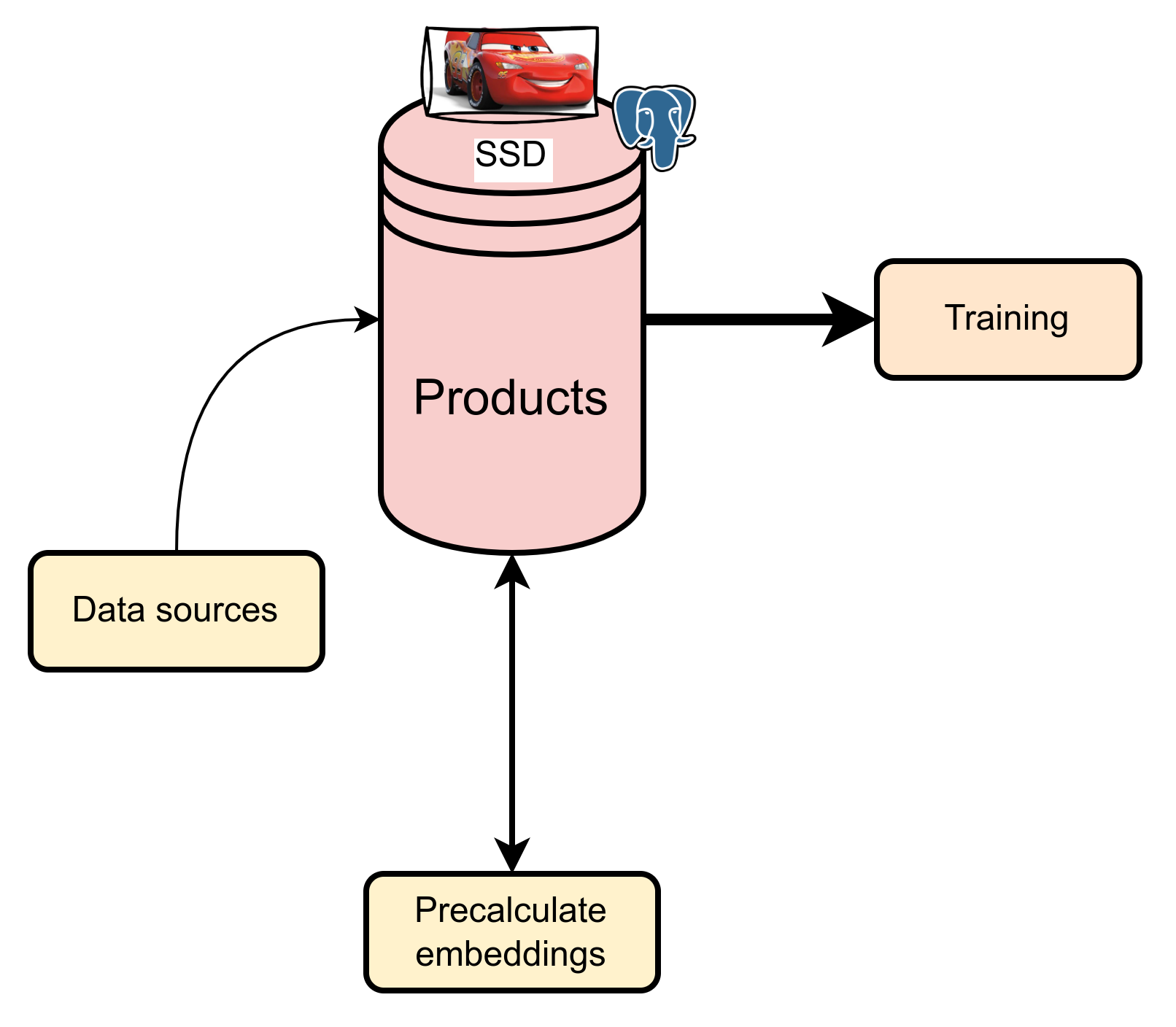
Attempts to use HDDs revealed issues with low input/output operations per second (IOPS), which significantly slowed down the pipeline.
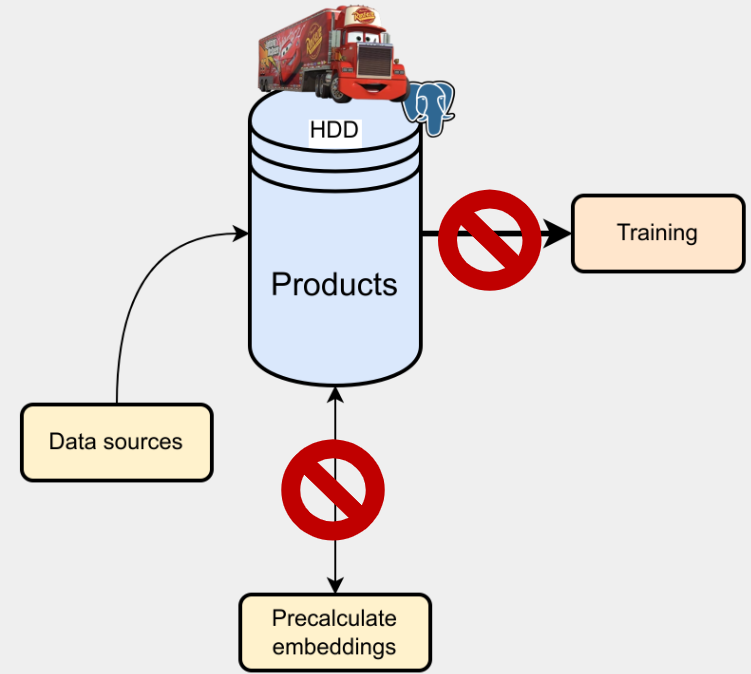
As a result, we adopted a multi-tiered approach: current data and cache are stored on fast SSDs, while historical data is stored on cheaper, high-capacity HDDs.
Conclusion
Building large, scalable systems comes with many challenges, but automating and isolating tasks is essential to allow teams to focus on system development rather than manual infrastructure management. Thanks to containerization, container registries, and CI/CD (Continuous Integration/Continuous Deployment) processes, we can simplify system deployment and maintenance. Proper data and hardware architecture, planned from the outset, is crucial to ensure optimal performance and scalability as the project grows.


