


Zero-shot models are helpful for prototyping machine learning projects because they generally do not need additional training to operate. CLIP, a popular model from OpenAI, does particularly well.
How CLIP works
CLIP (Contrastive Language-Image Pre-training) is a zero-shot model released by OpenAI in early 2021. It is trained on a variety of image-text pairs, making it effective for learning visual concepts through natural language.
CLIP is a very flexible and easily configurable model that has versatile applications
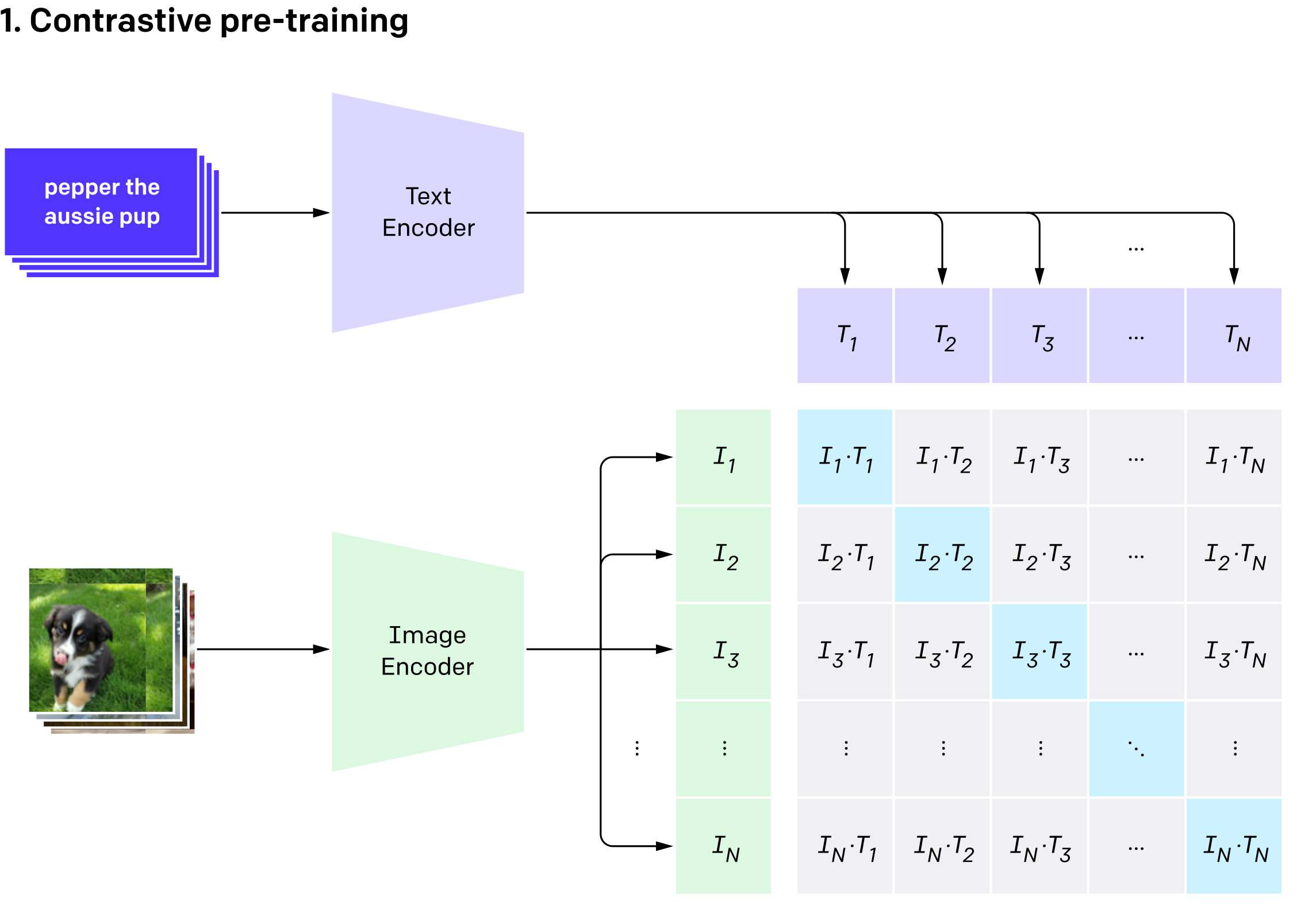
CLIP consists of two parts: an Image Encoder (which could be, for example, ResNet or Vision Transformer) and a Text Encoder (a Transformer-based model). Both of these models return vectors containing the encoded representation of a given image and text. These vectors are then compared using cosine similarity - the larger the value, the more similar the image and text are to each other.
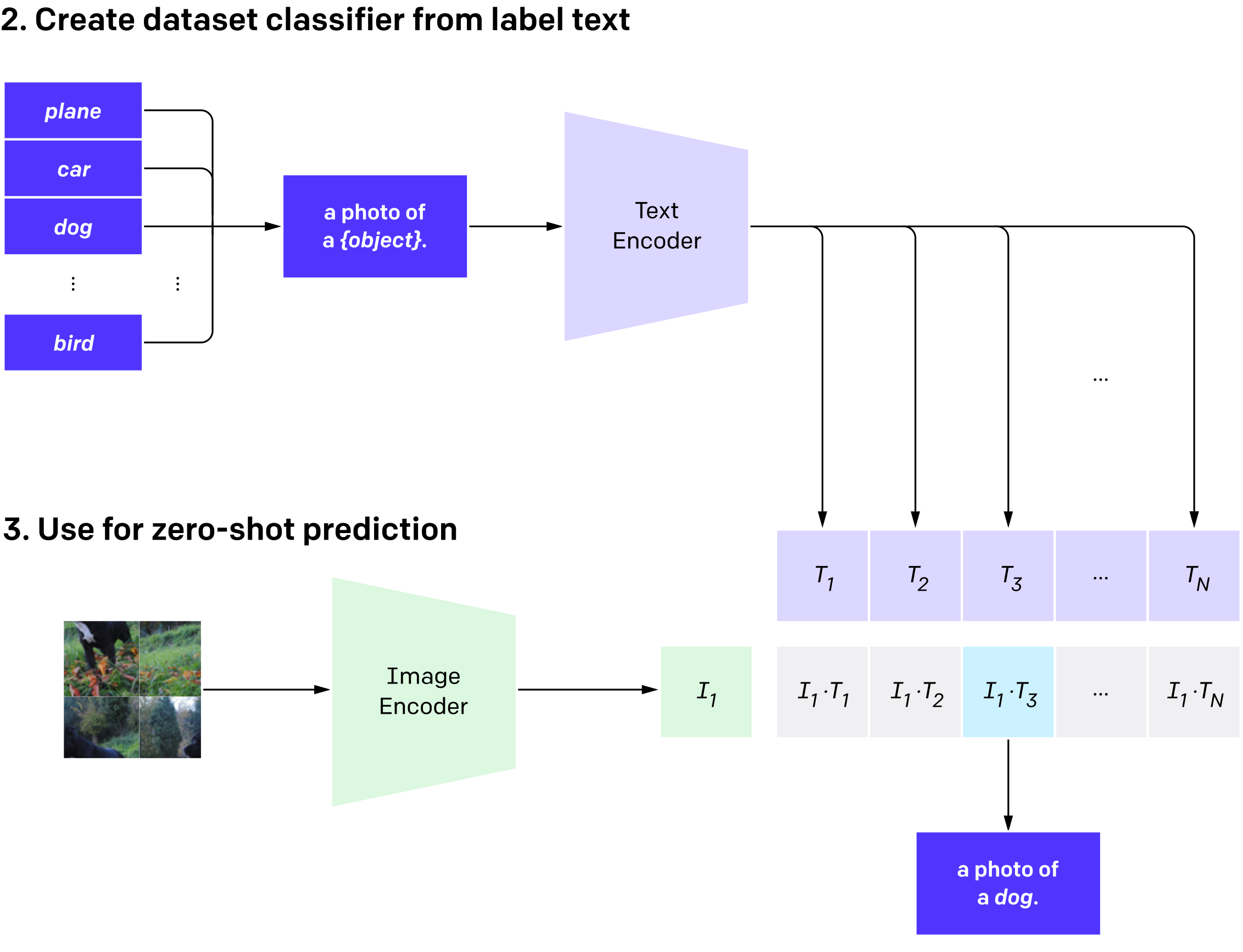
CLIP can be applied to any computer vision classification task by specifying the names of the categories to be recognized. All you have to do is prepare a set of categories and create a representation for each one using Text Encoder. Each image is then dropped into Image Encoder, and its output vector is compared with each of the test vectors. The one to which the image vector is most "similar" is selected as the predicted category.
Example of CLIP operation.The values on the right are additionally passed through softmax, which makes the models' operations similar to classical classification.
CLIP and prototyping
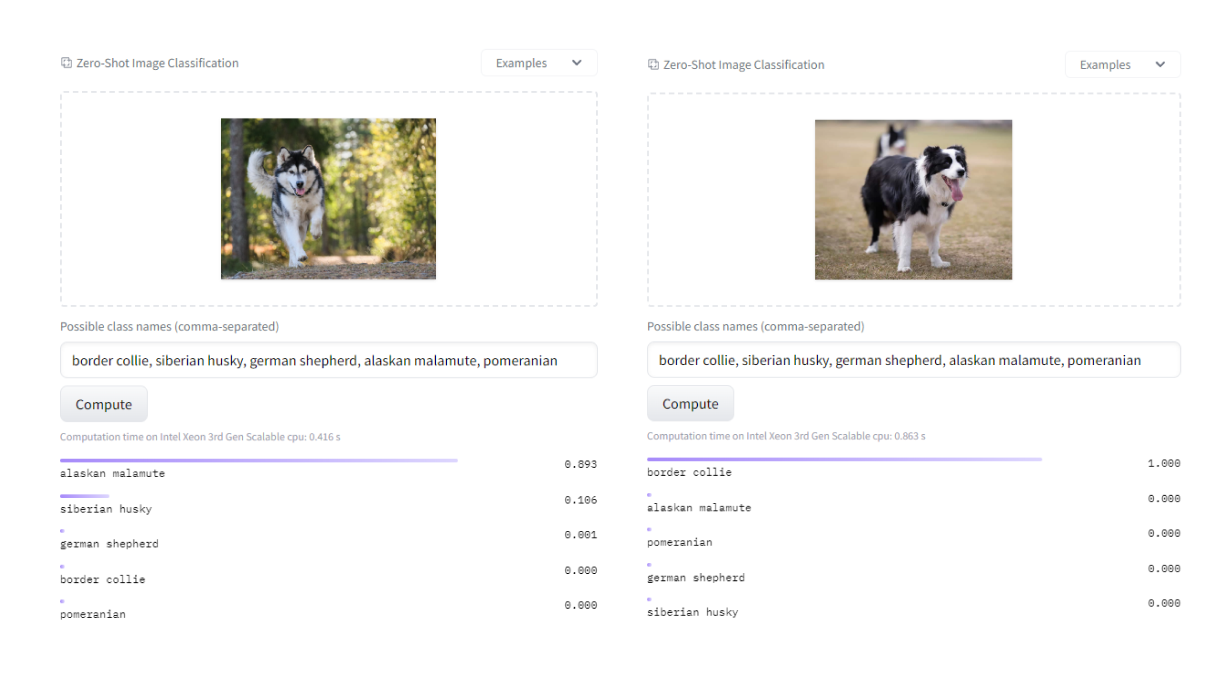
Thanks to its flexibility and versatility, CLIP can be used for the rapid prototyping of computer vision projects, without the need for additional training data. Suppose we need a model that recognizes a particular breed of dog on video, such as a Border Collie.
The simplest approach would be to compare the similarity (Cs) between the video frame (x) and the target prompt, i.e. "border collie" (yp). If the similarity is higher than some defined threshold (threshold), we recognize the presence of the dog in the image.
Mathematically it will be defined in this way:
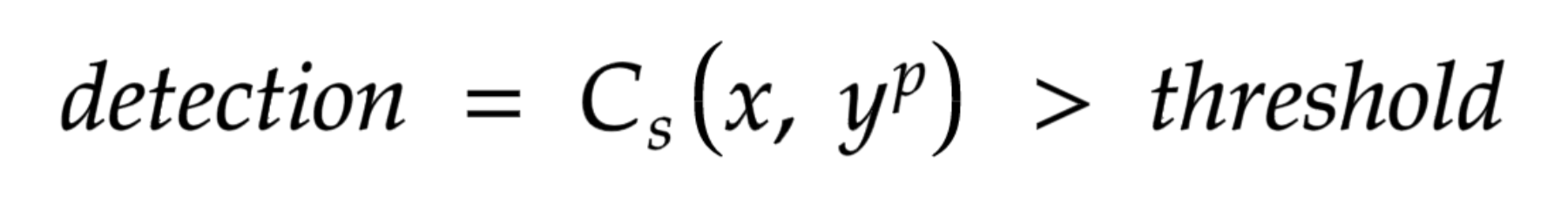
As you can see, CLIP handled the detection very efficiently:

Unfortunately, using the target prompt itself can cause false positive predictions to appear frequently - since we are acting on the similarity value between the image and the text, other dogs may be visually similar to our target breed.

To prevent this, we can introduce a more complicated condition based on "negative" (Yn) prompts, that is, a set of "categories" that we do not want to recognize - in our case, this will be a set of other dog breeds, e.g. Siberian husky, Alaskan malamute, etc. Introducing this set, we expect that our target class will have a higher similarity value with the image, than the other "negative" prompts. Mathematically, this condition presents itself as follows:
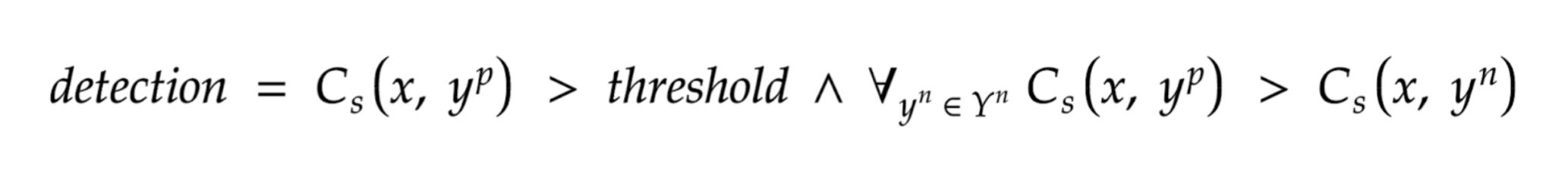


As can be seen from the above examples, the amount of false positive predictions has been significantly reduced, and the prediction of the border collie dog itself has not suffered from the introduction of the additional condition.
Prompt engineering
Thanks to CLIP's flexibility, we are not limited to a simple prompt like "border collie," but can experiment with different word configurations, finding the ones that are optimal for our situation.
For example, instead of simply writing "border collie," we can also use:
- an image of a border collie, a dog breed
- border collie, a dog breed
- a picture of a dog, a border collie breed
- etc.

In the graph above, you can see that the similarity values are similar for all prompts since they contextually mean the same thing. CLIP gives us virtually unlimited possibilities in forming text describing a picture, so we can form prompts containing additional conditions, e.g. "border collie with brown and white hair"
Limitations of CLIP
In addition to its advantages, CLIP also has a couple of limitations that you need to watch out for when creating prototypes. For example, CLIP is sensitive to the presence of text in an image. The model will focus on it instead of the content of the image, which can result in an incorrect prediction
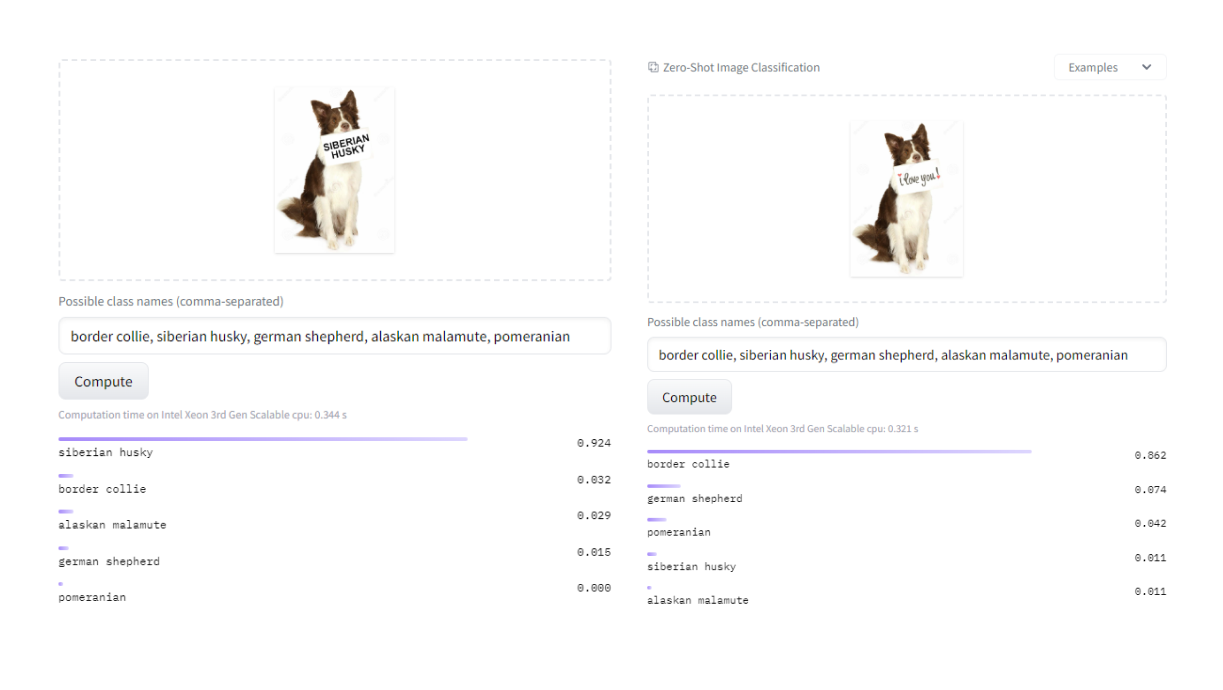
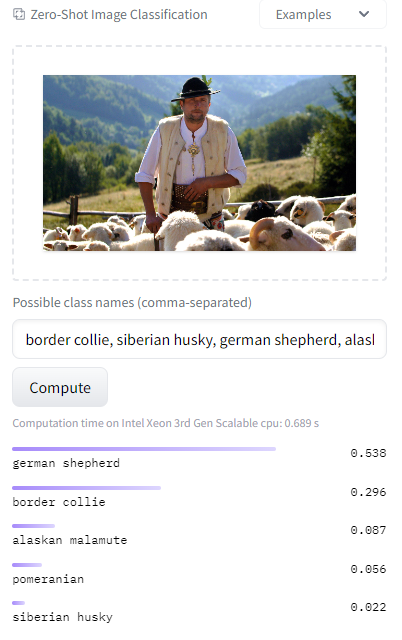
Another, example problem, is the different meanings of words, which can confuse the model. CLIP learns from pictures paired with captions, so completely different pictures with similar words in the description can be similar to CLIP. This can often happen for different brands or proper names like dog breeds. For example, we can accidentally detect German Shepherds if a human shepherd, or "shepherd," appears in the image
Summary
CLIP is a zero-shot model created by OpenAI, which is very flexible and versatile. Of the most important advantages of CLIP, we can highlight:
- Rapid prototyping of computer vision projects without the need for additional training data
- High flexibility in forming text describing images
However, CLIP, despite its versatility, also has some limitations to watch out for when creating prototypes, such as:
- sensitivity to the presence of text on the image
- different meanings of words, which can affect the erroneous prediction.
If you are interested in implementing solutions based on computer vision and natural language processing then be sure to write to us.


