


Speech recognition is prevalent in the modern world of technology - voice assistants, which enable hands-free dialing for smartphone users (helpful for drivers), voice control in car infotainment modules, voice searching - all of those appliances have automatic speech recognition as the core of their functionalities.
What is ASR?
It is a process of acquiring a transcribed sentence from a speech sample. It allows a user to communicate with the computer in the most natural, human-like way - by simply recording a speech and sending it to the algorithm, which will process the acoustic waves in order to translate the sentence from verbal format to the text one.
One may ask whether we really need such systems or if they are useful at all - using automatic speech recognition systems enable people with various physical disabilities to easily operate within the application. While not always being able to input the text by hand, the user can verbally interact with the system – similar situation is with driver operating the entertainment system by voice commands: he doesn’t have to take his hands of the steering wheel to change the radio station, answer the phone call or to set the route on the navigation system.
Automatic Speech Recognition allows a user to communicate with the computer in the most natural, human-like way - by simply recording a speech and sending it to the algorithm, which will process the acoustic waves in order to translate the sentence from verbal format to the text one.
How do we develop ASR solutions?
Creating a speech recognition system in conventional, deterministic way is a tremendous task - the algorithm would have to recognize usually over a hundred thousand of words: English has about 170,000 of words in current use, languages like Chinese has even more, which leads us to conclusion that classical approach to development of such system is inadequate. Those concerns may be solved by using machine learning - creating an AI-driven solution is beneficent both in terms of accuracy and development: training a model on sufficient amount of data is easier to execute and later, at the deployment stage, there are already mature tools to allow inferences on the model in the production environment.

The process of creating an automatic speech recognition system mostly consists of acquiring a sufficient amount of voice samples with required quality and using them as training data for an AI model. That’s the point which actually is the most troublesome - training a machine learning model needs data. A lot. If we want to have an accurate, versatile model, 10 hours of recorded speech samples is not enough, even 100 hours doesn’t mean much to the model - one of the best performing models for English has been trained on over 30,000 hours of voice samples!
Example - Arabic speech-to-text transcription
At Numlabs, we’ve tried to approach the speech recognition by creating an Arabic language speech-to-text transcription system. In our case, the model was using Mozilla DeepSpeech, open-source engine for speech recognition. The core of this engine based on techniques presented in Baidu's Deep Speech research paper. It allows to train a model for any language, requiring only the dataset and the alphabet with letters appearing in the transcription.
The dataset used for the training is Mozilla Common Voice - open-source dataset library, with speech samples from various languages, which are annotated by the community members. In case of Arabic, there are 49 hours of validated speech samples - it seems like an insufficient amount, but let’s try how accurate the model will be with such limited resources.
To show the importance of having as much speech samples as possible, we’ve trained 3 models: one with a tenth of an original dataset, second with a half of the dataset and the last one was using all samples for training. The results are presented on the histogram below:
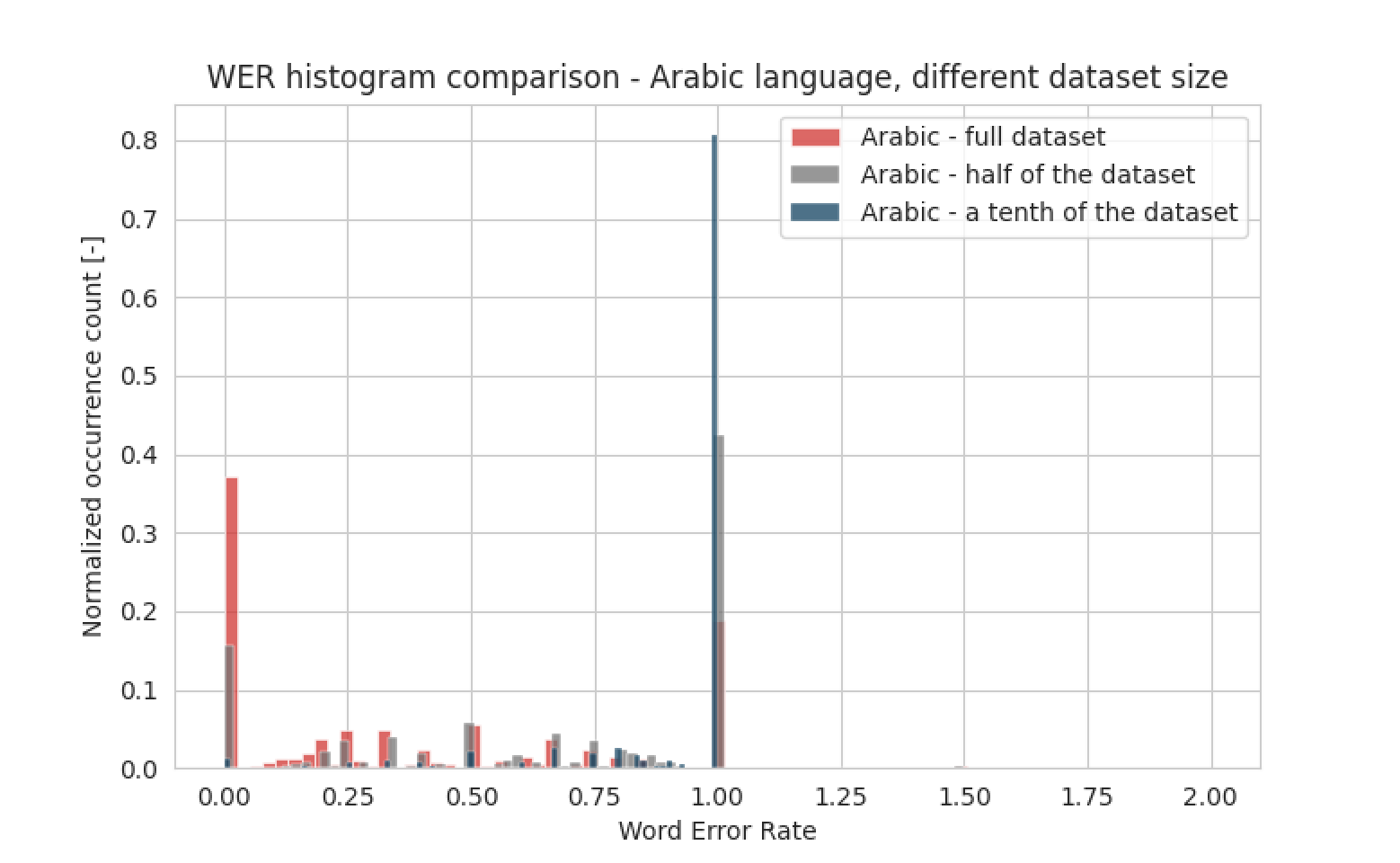
We can clearly see that the more samples we have, the better the results are. Model will never achieve accuracy of 100%, but it’s possible to get to the level of over 90%, provided big enough dataset.
Human performance versus AI
Now, we have a trained model for Arabic. But was it really necessary to develop an AI-driven solution? How would a person perform in such task? The research on comparing human performance with an algorithm has been carried out at Microsoft, with results presented in a paper. It states that accuracy for a careful human transcription is between 95.5 and 95.9%, while a quick transcription lowers it to 90.4%. Careful transcription usually takes a lot of time, sometimes even multiple hearings, while user often demands results as soon as possible. AI-powered solutions allow us to process the speech faster than the human, while maintaining even higher accuracy - the state-of-the-art models can achieve accuracy of over 98%!
Summary
The given article gives an idea about automatic speech recognition - what it is, why to use it, how to create it, and most important - how to make it work. It’s only an introduction to the topic, in the next article we will show more technical approach, with describing the model’s structure and showing prospects for development - since there’s a lot of area to explore.


