


The transition from GPT-3 to Chat-GPT represents a significant advancement in the field of artificial intelligence, marking a transformative leap in its evolution. While both models have left a profound impact on the field, it is essential to delve into the nuances that distinguish them and ascertain whether Chat-GPT is an enhanced iteration or an entirely novel creation. In this article, we'll explore the evolution of large language models (LLMs) and the role of Reinforcement Learning in shaping the modern landscape of chatbot development, unraveling the intricate mechanisms that have propelled these technologies to the forefront of innovation.
Why previous approaches aren’t enough.
While previous chatbot methods such as sequence-to-sequence (seq2seq), rule-based systems, and retrieval-based models have contributed significantly to the development of conversational AI, they often fall short in delivering natural, context-aware, and human-like responses. These methods often fail to capture complex nuances and context shifts, leading to dialogues that lack coherence and context relevance, resulting in less engaging interactions. Additionally, they struggle to handle open-ended questions, understand ambiguous language, or adapt to diverse conversation styles, ultimately limiting their capacity to provide seamless, human-like communication experiences that are increasingly sought after in today's digital landscape. To better understand the advancement, let's delve into one of the key methodologies employed.
What is Reinforcement Learning?
Reinforcement learning (RL) stands out distinctively from other machine learning paradigms due to its focus on learning through interaction with an environment to achieve a specific goal. Contrasting with supervised and unsupervised learning that depend on labeled datasets or established patterns, RL algorithms focus on sequential decision-making, aiming to maximize cumulative rewards in complex and unpredictable environments. This unique approach enables RL models to learn through trial and error, optimizing decision-making processes and long-term strategies based on the feedback received from the environment, thereby emphasizing the concept of delayed rewards and the exploration-exploitation trade-off. As a result, RL finds applications in dynamic scenarios where an agent must continually adapt to changing circumstances, making it a key player in domains such as robotics, game playing, and autonomous systems, but recently it found a new application in fine-tuning large LLMs.
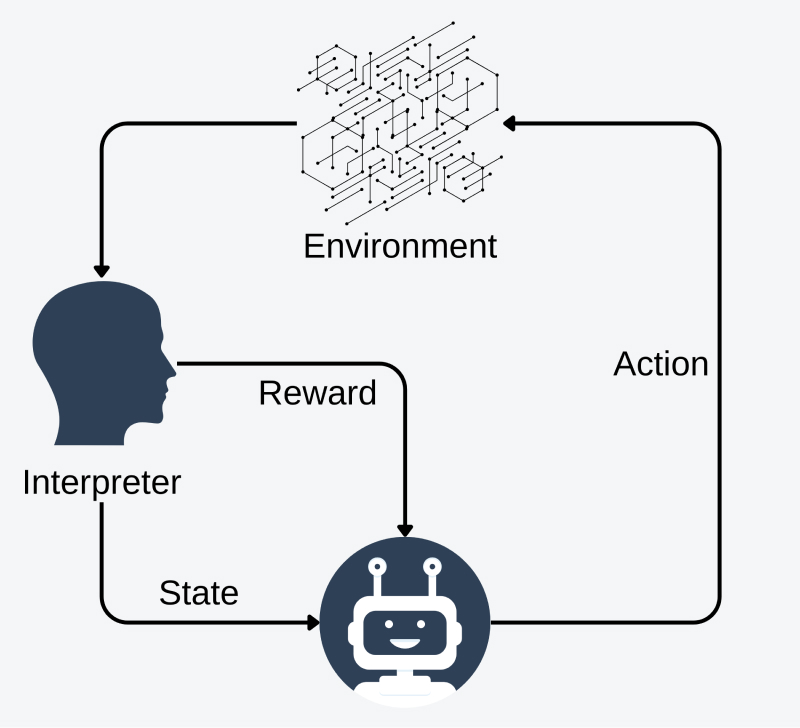
Reinforcement Learning from Human Feedback (RLHF) - how does it work?
RLHF integrates human input into the reinforcement learning process, utilizing evaluations or demonstrations provided by humans to direct an AI agent's learning path. Through a combination of human-provided feedback and trial-and-error exploration, RLHF enables the agent to learn complex tasks more efficiently, bridging the gap between human intuition and machine learning capabilities, in natural language processing those complex tasks can be understanding comedy, politeness etc. In order to apply RLHF to LLMs we need to divide it into three main steps:
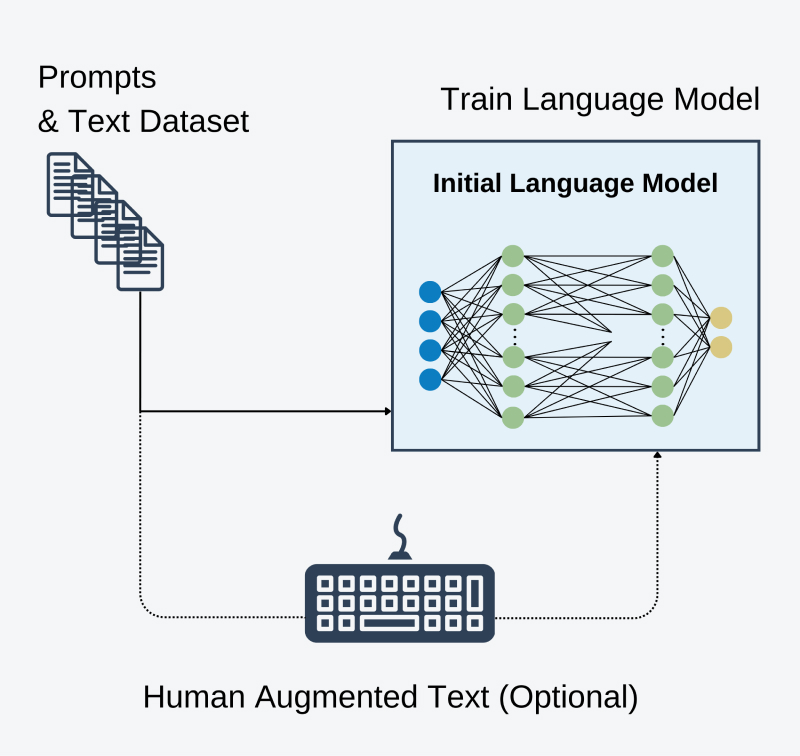
- Pre-Train Language Model using standard auto-regressive procedure.
This is the standard LLM learning procedure when we train our model to generate next tokens based on the previously seen ones. This step is optional because currently a lot of open LLMs are trained on the datasets so big that it has already seen the multiple examples of conversions as well as it has a deep understanding of human language.
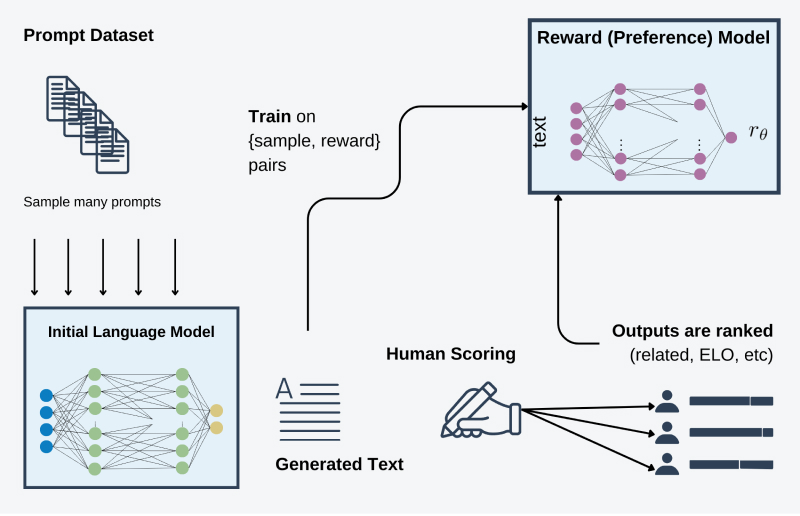
- Train Reward Model using ratings acquired from human experts.
To enhance the comprehension of intricate linguistic forms like humor and metaphors within human language, expert human reviewers assess the responses generated by the trained model, assigning ratings to each (for example ELO model can be used). This process helps establish a ranking or rating system for all the responses, enabling the model to associate rewards in the subsequent steps. Consequently, the model will be guided to generate the highest quality answers, informed by the associated rewards acquired during this process.
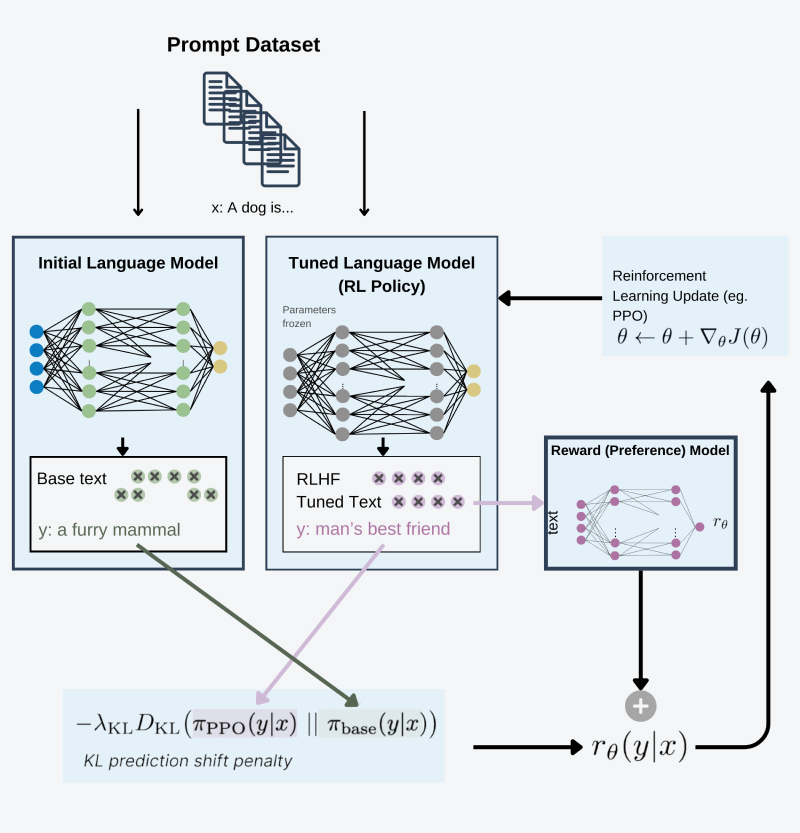
- Fine tune model using RL dynamics, while using rewards acquired from trained reward model.
This step probably needs additional explanation, in order to restrict model not to exploit the rl mechanism and learn to produce useless responses to maximize rewards we are keeping two versions of the LLM in order to keep all the existing information and understanding of the human language. One of the models has frozen weights and during loss calculation we apply a regularization term (KL Divergence) that controls the weights not to change too much from the original model. Excerpts from using reward model and this regularization procedure the fine-tuning is the standard RL experiment where action space are the tokens from models vocabulary and state space is distribution of possible input tokens.
Can RLHF be used for other tasks?
Actually RLHF is a procedure that out-dates the LLMs itselfs it was originally used for standard RL tasks such as robotics.
Recently, researchers from Nvidia have applied this method in learning a variety of tasks within Minecraft, developing a model known as MineCLIP. An open world game with complex mechanics like crafting, building and exploring. The collection of tasks vary from really simple ones like equipping items, to build complex structures etc. First stage of training is creating a dataset. It is used by downloading youtube videos with transcripted audio. Then a human expert is used to properly score the scrapped transcription, this way we collect multiple tasks with the properly scored description of it.
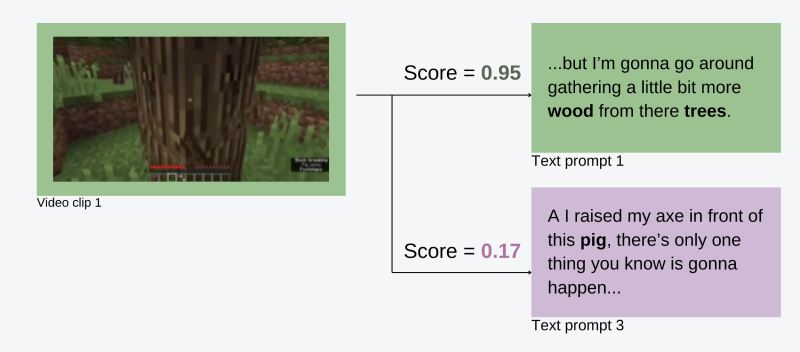
Summary:
RLHF is a powerful approach for helping Language Models with substantial domain knowledge to better comprehend intricate subjects that are not easily encapsulated by mathematical formulas.
However, it's essential to clarify that RLHF necessitates a dataset that has been labeled by human experts, making it non-accessible for widespread use. This process typically demands a substantial budget or a large community effort to collect the necessary examples.
Addressing the initial query: How does Chat-GPT (original version) differ from GPT-3? Although it is fundamentally the same model, its performance has been significantly enhanced through RLHF fine-tuning.


