


In the previous article, we’ve made an introduction to the topic of speech-to-text conversion: what it is, how it’s made, where it’s used. Now, let’s dive deeper into topic and try to understand the logic behind the model creation and training for our system of Arabic automatic speech recognition.
We’ve used Mozilla DeepSpeech engine for development of our model - apart from the ease of use, it has one major advantage - Mozilla offers a pretrained English model with WER 7.06%, which can be used as a base for transfer learning - adjusting the weights in the upper layers while preserving the lower ones. Our dataset is Mozilla Common Voice, with 49 hours of transcribed speech samples, varying in length from 5 to 20 seconds.
How to measure the accuracy
To easily measure the model’s accuracy, the word error rate (WER) has been introduced: it describes, how many words in the sample has been transcribed mistakenly - either there was a typo in the word (substitution), extra word has been inserted to the sample (insertion), or a word hasn’t been transcribed at all (deletion). For example, the best performing model for English speech recognition has a WER of 0.019, which means that about 2% of words in a sentence may have an error in its transcription. The WER can also be shown as a percentage value, where WER of 1 is equal to 100%. The smaller the WER is, the better.

There are some other metrics available, similar to WER, such as character error rate (CER) or sentence error rate (SER), but we’ve chosen to use word error rate as our main metric, due to the fact that it’s the most common one, used in many research papers about automatic speech recognition.
Training a model
The model used for our Arabic automatic speech recognition is DeepSpeech2 - a recurrent neural network, trained to ingest speech spectrograms and generate transcriptions. The preprocessing is already implemented in Mozilla DeepSpeech, therefore we didn’t have to develop our own processing layer.
Next step was to prepare the data for training - the Common Voice dataset already has .tsv files with transcriptions, which we have to convert into comma separated files (.csv), so the DeepSpeech will be able to process them. The data was split into training, testing and validation sets in proportion of 50%/25%/25% of original dataset.
Because of a small dataset, we’ve decided to use transfer learning - the English model became a base for training an Arabic speech-to-text model. The 3 upper layers were retrained, with the remaning layers unchanged. The Deep Speech model was trained until it converged - when overfitting started, the training was interrupted. The trained model achieved WER of 34%, which means that roughly a third of transcribed words has an error - quite a lot, but given the limited dataset size, it could have been much worse. Compared to the English model, the accuracy is almost 5 times lower, due to having only 49 hours of samples versus thousands used for training the English one. The comparison may be seen on this histogram:
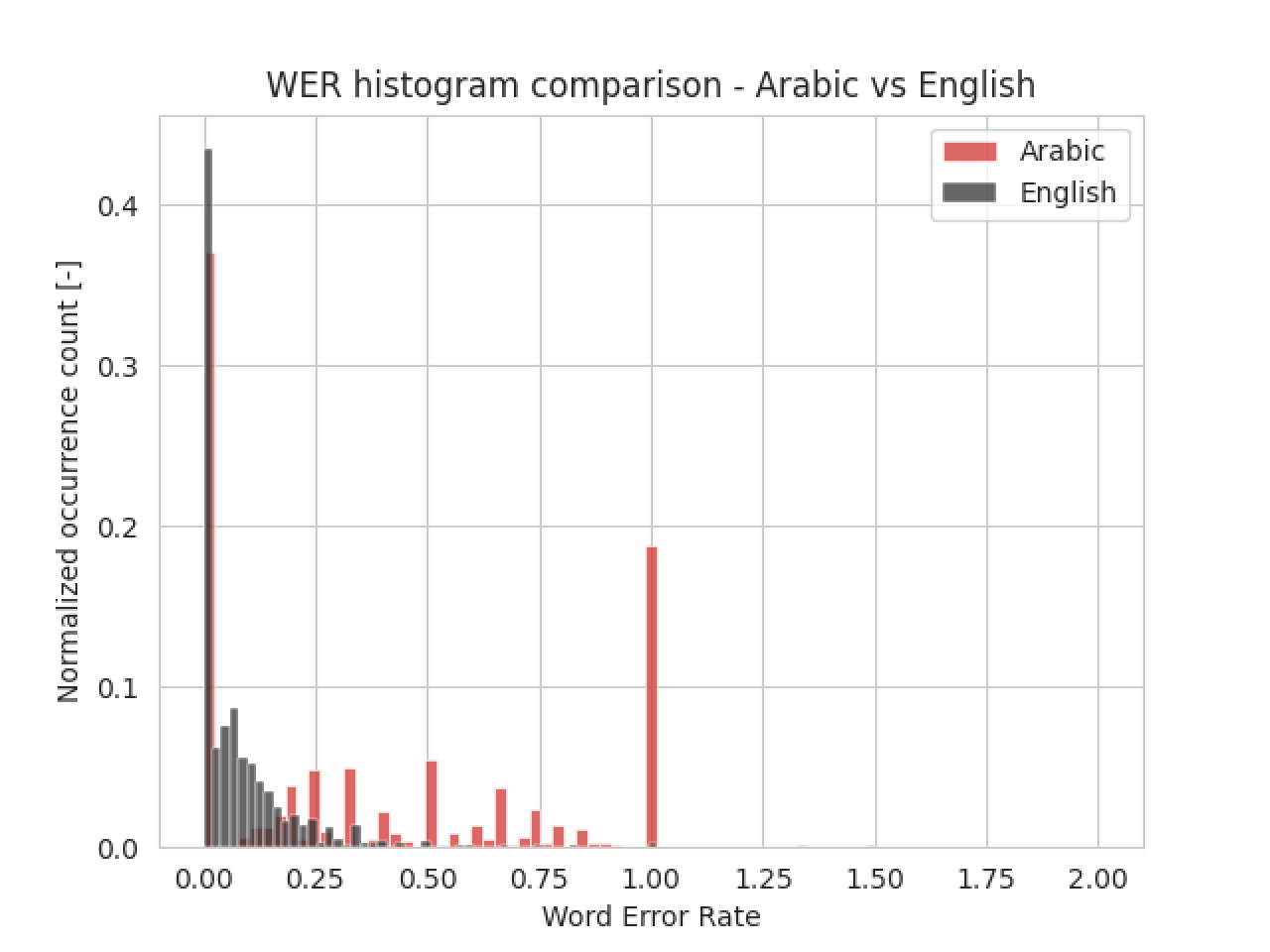
It’s clearly visible that training the model on 49 hours of voice samples is inefficient - there is not enough data for the model to train on, even for a transfer learning.
Language Model - boosting the accuracy
Next of DeepSpeech’s advantages is that an additional language model, called scorer, may be used to verify the transcription - we can create a textual model out of a text corpus, and use it as a spellchecker: since language model is capable of correcting the grammar, the transcription model’s output may be verified and corrected, if needed. The language model needs to be created using KenLM - an external library for language model development.
The best performing model for English speech recognition has a WER of 0.019, which means that about 2% of words in a sentence may have an error in its transcription. The WER can also be shown as a percentage value, where WER of 1 is equal to 100%. The smaller the WER is, the better.
Although, usage of scorer is insignificant when training a model to transcribe a lexically broad dictionary, it’s profitable to use it only when we are trying to recognize a small subset of words or when our dataset is big enough, then the language model is fine-tuning the transcription’s model output. In our system, applying an external language model allowed us to reduce WER from 37% to 34% - not an extremely spectacular result, but it did increase model accuracy.
Summary
In this article, we’ve shown how to train a DeepSpeech model to transcribe the voice samples and how to improve the model’s accuracy with an external language model. Of course, there is a lot to improve - we can try to use different model architectures than DeepSpeech or try to fine-tune our current model. ASR is a vast topic, constantly evolving - both in terms of applications and the solutions’ quality.


