


Celem artykułu jest wprowadzenie czytelnika w tematykę analizy szeregów czasowych z punktu widzenia data science. Skupimy się na podkreśleniu różnic pomiędzy szeregami a innymi rodzajami danych i wprowadzimy wybrane metody stosowane w analizie szeregów czasowych.
Czym jest szereg czasowy?
Na nasze potrzeby szeregiem czasowym będziemy nazywali dane, których jednym z pól jest czas. Takim szeregiem jest na przykład pomiar prędkości nadjeżdżających samochodów w przypadku gdy zapisywana jest data pomiaru oraz prędkość. To w jaki sposób zapisywany jest czas nie ma znaczenia. Może być to na przykład ilość sekund która upłynęła od początku 2001 roku. Skoro już wiemy, czym jest szereg czasowy odpowiedzmy sobie na pytanie co odróżnia go od zwykłych danych? Wróćmy do przykładu modelu opisującego ruch samochodów na danym odcinku. Jednym z pierwszych kroków podczas analizy jest wyznaczenie średniej i odchylenia standardowego prędkości samochodów, jeżeli uwzględnimy czas możemy wyznaczyć je dla każdej z godzin osobno, co pozwala nam stwierdzić chociażby o której porze dnia kierowcy najczęściej przekraczają dozwoloną prędkość, lub w które dni ruch jest większy niż zazwyczaj. Czas nadaje danym porządek. Aby w pełni wykorzystać wiedzę zawartą w szeregach czasowych będziemy musieli wprowadzić kilka nowych metod analizy.
Zbiór danych
W tym artykule będziemy używali zbioru “Advance Retail Sales Time Series Collection” pochodzącego z serwisu Kaggle. Składa się on z 28 przebiegów czasowych. Dane dotyczą sprzedaży detalicznej wybranych grup produktów na przykład: odzieży, żywność czy artykułów ogrodniczych. W naszym przypadku punkty są równo oddalone od siebie w czasie, jednak w ogólności czasy pomiarów mogą być zupełnie dowolne. Skoro mamy już przygotowane dane narysujmy je. Bardziej niż same wartości i jaki konkretnie produkt przedstawia dany wykres interesuje nas różnorodność ich kształtów.
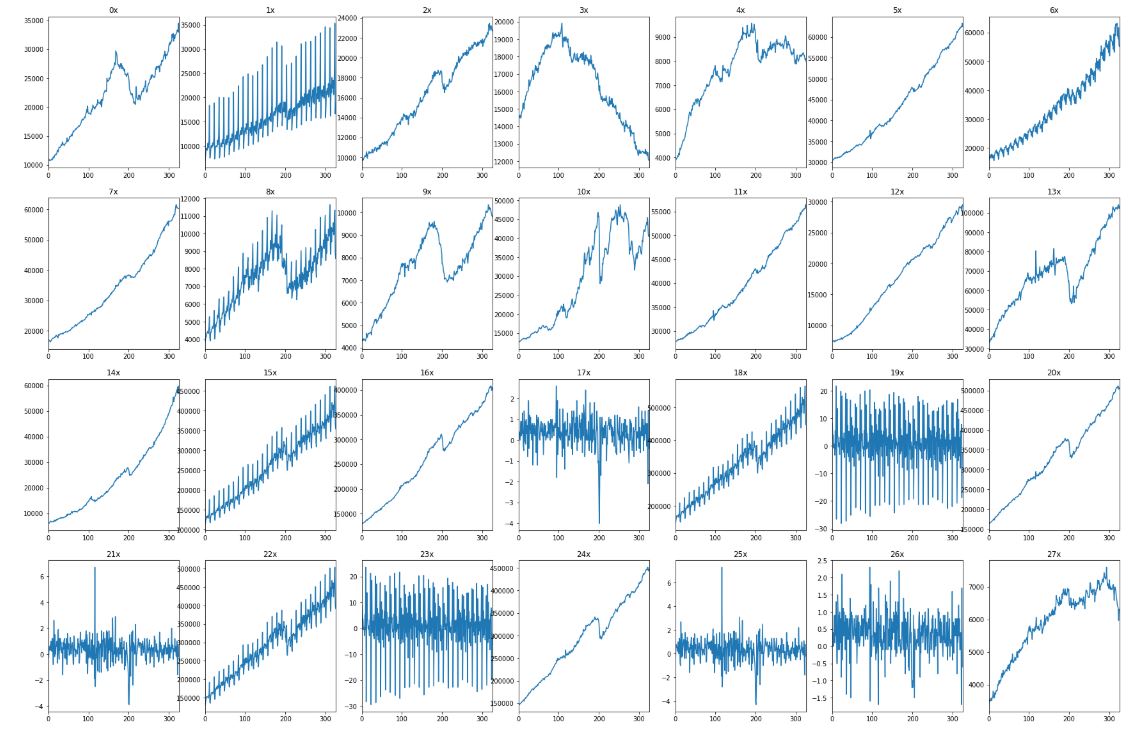
Niektóre stale rosną, inne odcinkami rosną a następnie maleją, a pozostałe oscylują wokół ustalonej wartości. W tym wpisie przyjrzyjmy się bliżej wykresowi “6x” znajdującemu się w prawym górnym rogu.
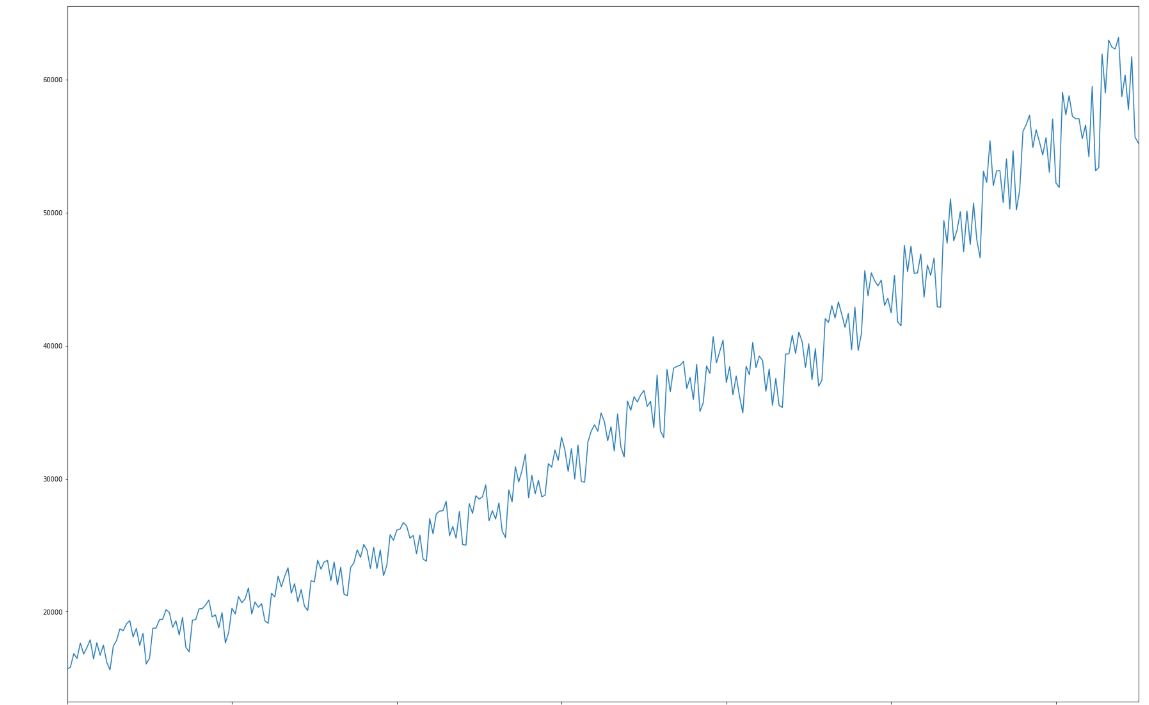
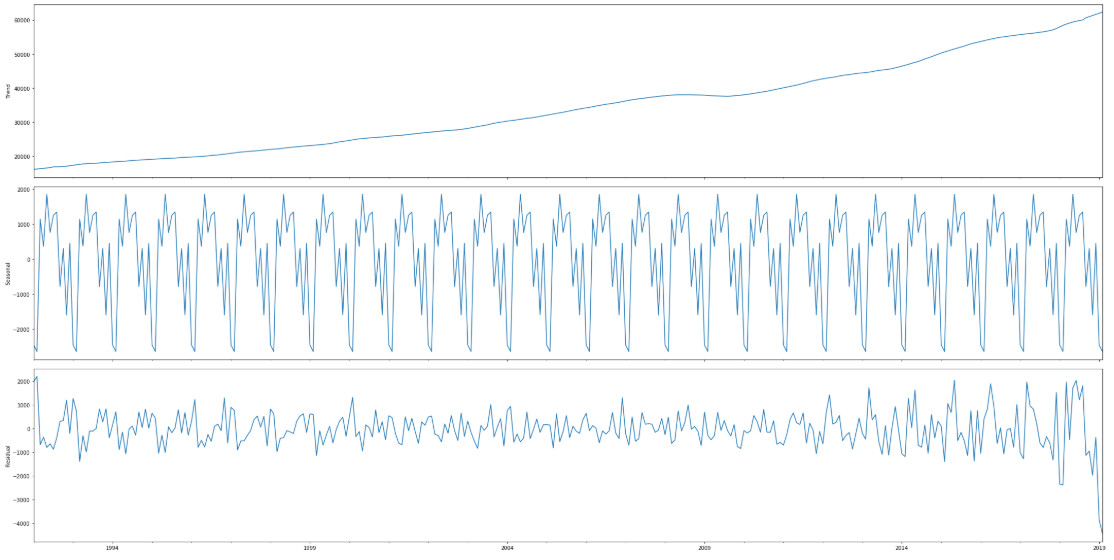
Co możemy o nim powiedzieć? Po pierwsze wraz z biegiem czasu wartości sprzedaży rosną. Poza wzrostem, który można aproksymować na przykład liniowo, bądź wielomianem, drugim komponentem jest przebieg zdradzający pewne okresowe zachowania. Standardowa metoda polega na rozłożenie przebiegu na sumę trzech sygnałów: trend (w tym przypadku aproksymowany funkcją nieliniową), część okresową - sezonowość, oraz tak zwane residuum czyli pozostałość.
Trend jest o rząd wielkości większy niż pozostałe składowe, ma to duży wpływ na korelacje między przebiegami, ponieważ większość z nich zawiera trend. Na pierwszym wykresie widzimy wartości funkcji korelacji obliczone dla niezmienionych przebiegów:
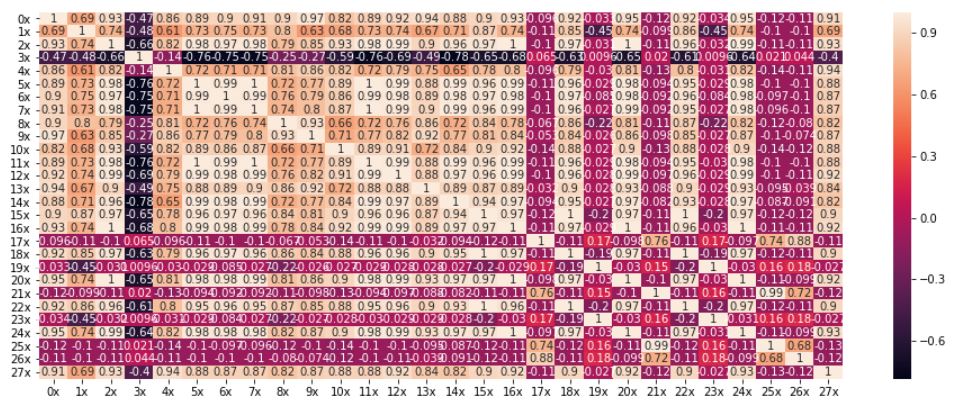
W tym przypadku pierwsze 17 przebiegów jest bardzo mocno skorelowane, niektóre przyjmują wręcz wartość 1 co oznacza, że pliki zawierają dokładnie te same dane (tak jest w rzeczywistości) lub w pewien sposób liniowo przeskalowane. Macierz korelacji po usunięciu trendów (przy założeniu, że trendy to funkcje liniowe) wygląda już zupełnie inaczej.
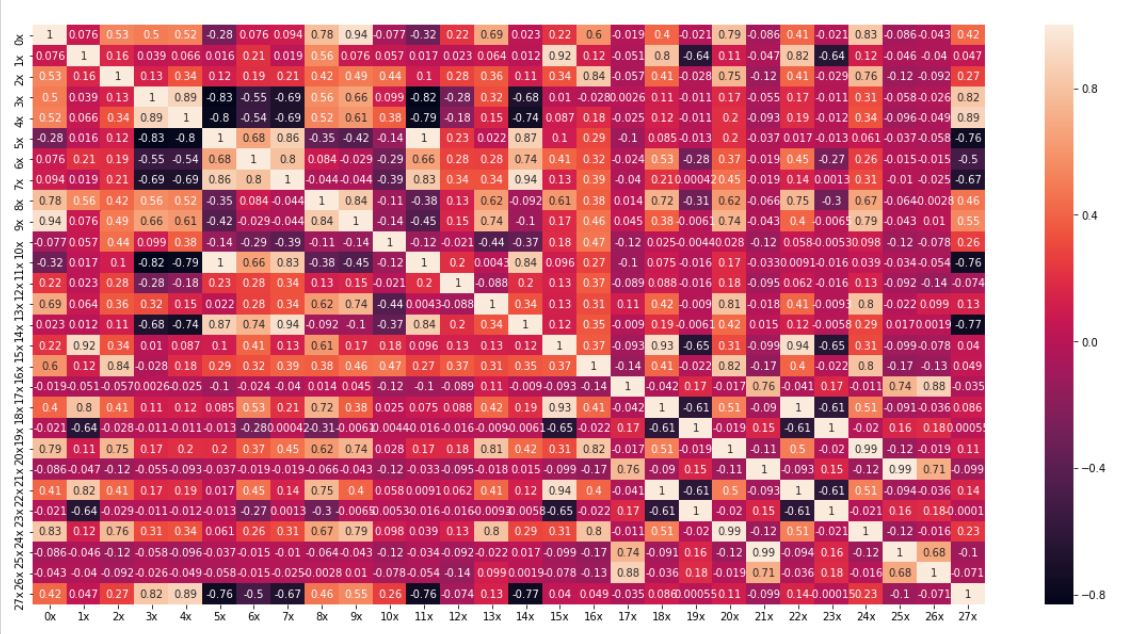
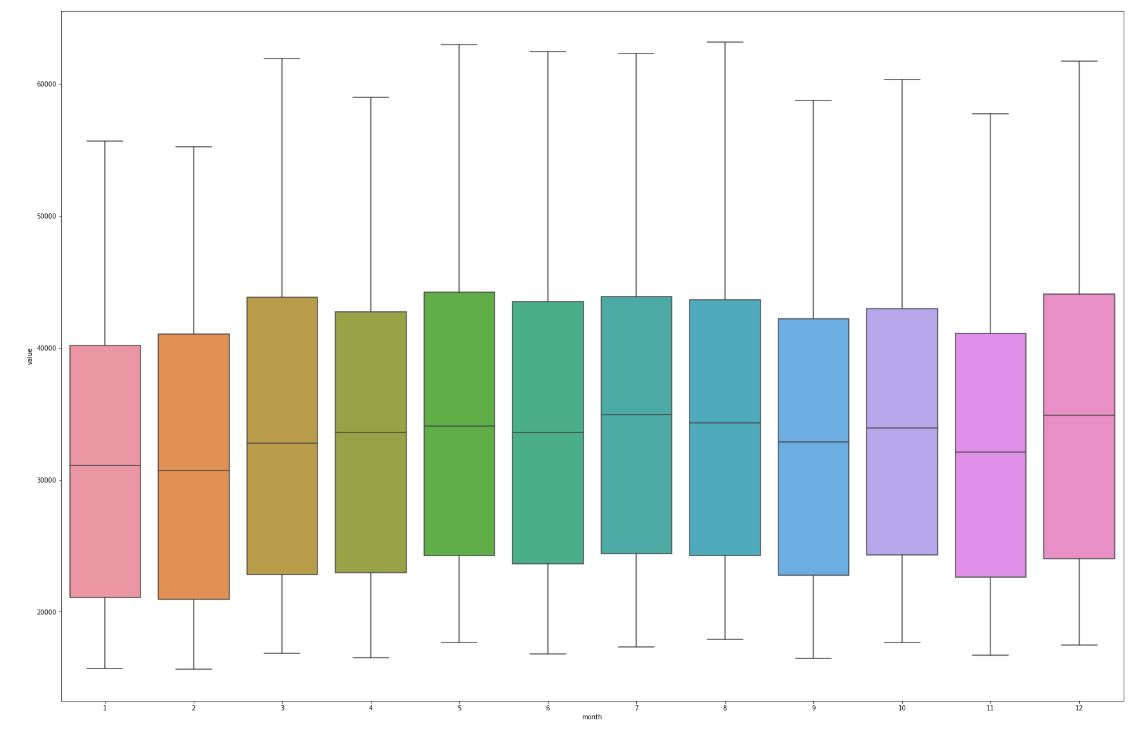
Za większością zależności stała rosnąca sprzedaż (trend), a korelacje wywołane sumą składowych sezonowej i residuum są rzadsze. Usunięcie trendu uwypukla lokalne własności przebiegu. Poniżej znajduje się wykres pudełkowy podsumowywujące sprzedaż w konkretnych miesiącach.
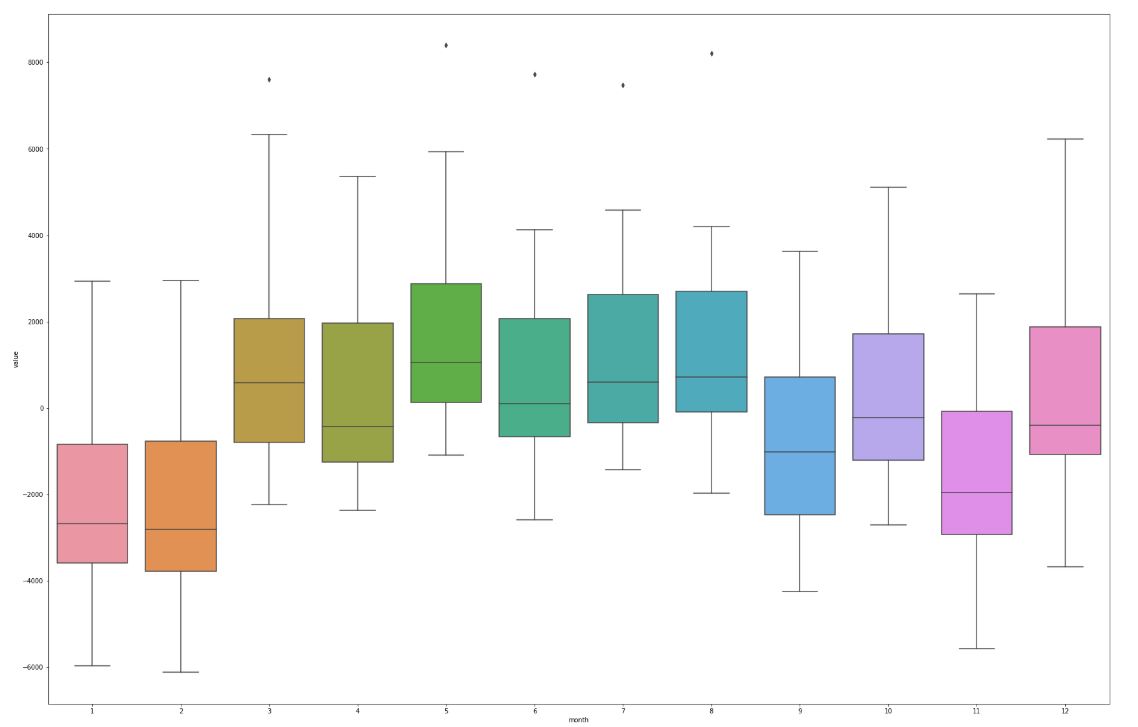
Znacznie ciekawszy jest jednak ten sam wykres jednak dla przebiegu, w którym usunięto liniowo aproksymowany trend. Różnice pomiędzy miesiącami są znacznie lepiej widoczne.
Analiza sezonowości
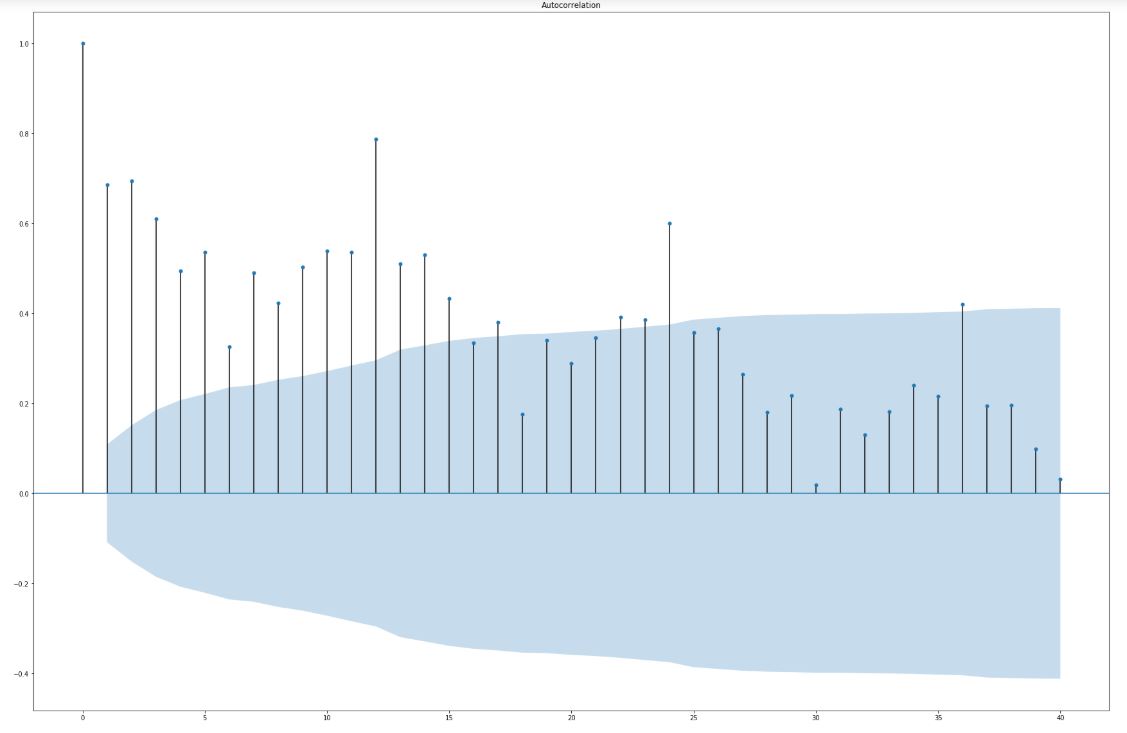
W celu analizy sezonowości mamy do dyspozycji kilka innych metod na przykład funkcję autokorelacji. Liczymy ją w następujący sposób: n-ty wyraz to współczynnik korelacji oryginalnego szeregu z szeregiem przesuniętym o n próbek. Ideę można zilustrować na przykładzie funkcji sinus. Przesunięcie o n elementów to dodanie przesunięcia fazowego. Obliczenie korelacji pokaże nam jak bardzo przesunięty wykres jest podobny do zwykłego sinusa. Jeśli przesunięcie będzie równe okresowi sinusa to otrzymamy dokładnie taki sam przebieg i korelacja wyniesie 1.
Przedział ufności dla autokorelacji
Jak więc rozpoznać czy korelacja spowodowana jest jakąś własnością szeregu a nie czystym przypadkiem? Niebieski obszar to tzw. 95% przedział ufności. Oznacza to, że jeśli wykres znajduje się poza nim to mamy 95% pewności, że korelacja jest istotna, czyli nie jest przypadkowa a wynika z zależności kształtujących przebieg. Jest to oczywiście uproszczona interpretacja. Poniżej ograniczyliśmy się do autokorelacji z maksymalnym przesunięciem o 40 próbek. Jak widzimy, funkcja ta ma wyraźne maksima co 12 próbek czyli 12 miesięcy. Jest to kolejna przesłanka co do istnienia okresowości w sprzedaży w cyklu rocznym.
Stacjonarność szeregu czasowego
Ostatnim zagadnieniem, które chcę poruszyć w tym wpisie jest stacjonarność. Szereg (a w zasadzie proces stochastyczny, przy czym oba pojęcia są mocno związane) nazywamy stacjonarnym (bardziej formalnie: słabo stacjonarnym) jeśli ma niezależną od czasu: wartość średnią, wariancję i autokorelację. Szereg “6x” jest oczywiście niestacjonarny ze względu na występujący w nim trend oraz sezonowość, które mają wpływ na wartość średnią. Szeregi stacjonarne są zdecydowanie łatwiejsze w analizie, sporo popularnych modeli wymaga również aby szereg był stacjonarny. W zależności od tego czym spowodowana jest niestacjonarność możemy wykorzystać kilka metod sprowadzenia szeregu do postaci stacjonarnej. Jedna z nich, likwidująca liniowy trend, polega na zastąpieniu szeregu Y[0], … Y[325] różnicami w postaci X[0] = Y[1] - Y[0]. Po tym zabiegu nasz szereg wygląda następująco.
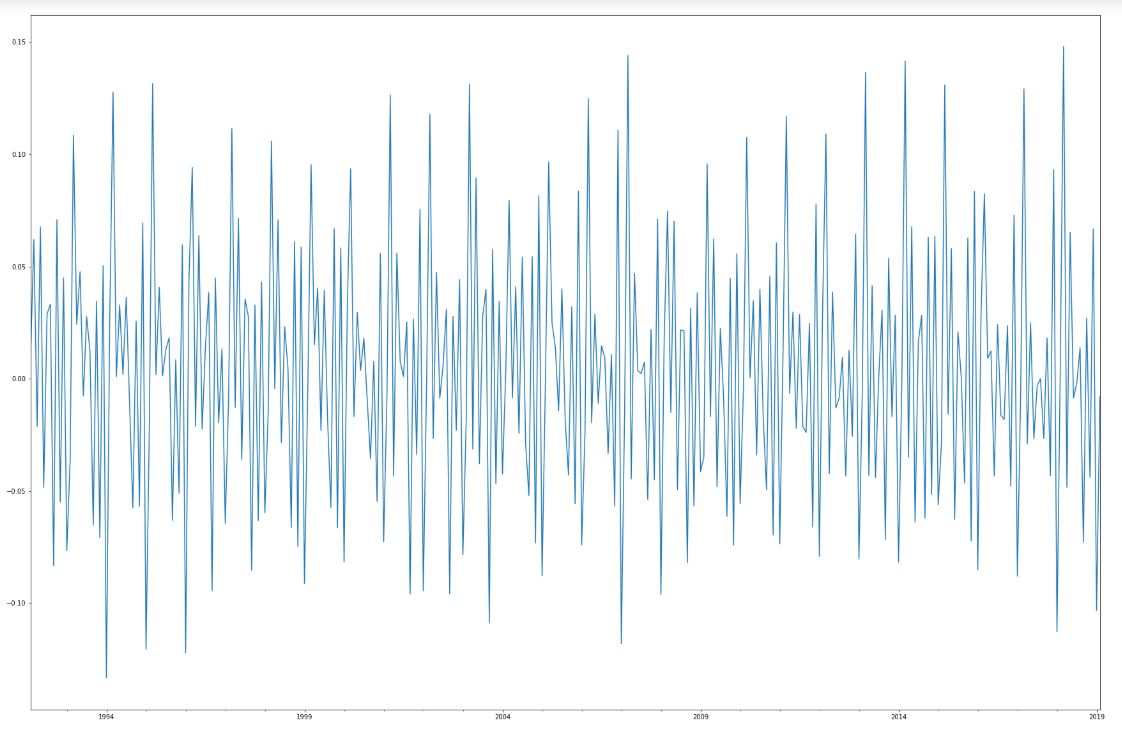
Weryfikacja stacjonarności
Jak widać pozbyliśmy się trendu. Czy jednak sprawiło to że proces stał się stacjonarny? Nie zapominajmy o części sezonowej, która być może jest na tyle istotna, że należy ją usunąć. Tak jak w przypadku autokorelacji istnieją metody pozwalające w stopniu lepszym niż “na oko” to ocenić. W tym celu stworzono kilka testów statystycznych. Przedstawimy tutaj jeden z nich - test KPSS nazwany tak od nazwisk twórców: Kwiatkowski–Phillips–Schmidt–Shin. Typowa budowa testu statystycznego jest następująca. Stawiamy dwie hipotezy zerową oraz alternatywną, które się dopełniają. W tym przypadku hipoteza zerowa testu mówi, że analizowany szereg jest stacjonarny. Hipotezą alternatywną jest stwierdzenie, że szereg nie jest stacjonarny. Wybieramy poziom istotności, czyli prawdopodobieństwo, że odrzuciliśmy hipotezę zerową pomimo, że była prawdziwa, zazwyczaj jest to 5 %. Pamiętajmy, że operujemy na danych losowych a nie określonej konkretnym równaniem funkcji, stąd zawsze mówimy o prawdopodobieństwie a nie pewności. Sam test to porównanie wartości obliczonej ze wzoru na tak zwaną statystykę testową i wartości krytycznej zależnej od poziomu istotności. Wzory te są przygotowane dla konkretnego testu, dzięki oprogramowaniu statystycznemu nie musimy ich liczyć na piechotę. Najważniejsza jest znajomość ich interpretacji. Jeżeli wartość statystyki jest większa od wartości krytycznej odrzucamy hipotezę zerową i przyjmujemy hipotezę alternatywną czyli szereg nie jest stacjonarny. Dla 5% poziom istotności wartość krytyczna wynosi 0.463, wartość statystyki obliczona dla nowego szeregu 0.061922 a dla szeregu “6x” bez zmian 1.904594. A więc udało się, nowy szereg w przeciwieństwie do starego możemy uznać za stacjonarny.
Podsumowanie
Podsumowując, po przeczytaniu tego wpisu powinna być Ci bliższa idea szeregu czasowego. Nauczyliśmy się przekształcać go i wydobywać z niego funkcyjne zależności takie jak trend i sezonowość. Na końcu wprowadziliśmy pojęcie stacjonarności. Wiemy już jak sprowadzać niektóre szeregi do postaci stacjonarnej oraz sprawdzać czy rzeczywiście nimi są. Uzbrojeni w tę wiedzę jesteśmy gotowi do nauki modelowania szeregów w celach predykcyjnych.


