


Wraz z rosnącą liczbą projektów opartych na uczeniu maszynowym, Machine Learning Operations (MLOps) staje się kluczowym elementem zarządzania pełnym cyklem życia modeli machine learningowych. Obejmuje to zbieranie danych, trening, ewaluację, wdrażanie, monitorowanie oraz aktualizację modeli. Wiele obecnych rozwiązań MLOps skupia się na zarządzaniu pojedynczymi modelami lub niewielkimi ich zbiorami, które można zdefiniować manualnie. Co jednak w sytuacji, gdy jeden model nie wystarczy, a złożony system wymaga wielu modeli działających na różnych zestawach danych? Na przykład, w kontekście analizy sprzedaży lub prognoz dla różnych regionów czy segmentów klientów, każdy z nich może wymagać własnego, wyspecjalizowanego modelu. Jak skutecznie zarządzać i monitorować dziesiątki, a nawet setki podobnych modeli w sposób zautomatyzowany i skalowalny? Jak sprawić, by dodawanie kolejnych modeli i pipeline’ów było szybkie i bezproblemowe? W tym artykule przedstawię, jak podeszliśmy do rozwiązania tego wyzwania, omówię naszą architekturę oraz napotkane trudności.
Wstęp do Projektu
Projekt realizowany był dla klienta integrującego sklepy internetowe z różnymi platformami typu marketplace, takimi jak Allegro, eBay czy Amazon. Celem było stworzenie systemu, który automatycznie klasyfikuje produkty do odpowiednich kategorii na tych platformach, bazując na wprowadzonej przez użytkownika nazwie produktu. Główne wyzwanie stanowiło stworzenie modelu klasyfikacji tekstu, który poradzi sobie z przypisywaniem produktów do tysięcy kategorii dostępnych na każdej platformie.
Wyzwania
- Duża liczba klas: Dla przykładu, Allegro oferuje 13 788 kategorii produktów.
- Wymagania danych: Aby model był efektywny, potrzebujemy co najmniej 2000 nazw produktów na każdą kategorię.
- Dynamiczne drzewo kategorii: Kategorie produktów na marketplace’ach często się zmieniają, co wymaga regularnych aktualizacji danych.
- Ograniczony dostęp do danych: Wiele sklepów nie udostępnia danych w przystępny sposób.
- Skalowalność: Konieczność obsługi wielu sklepów wymaga elastycznego i łatwego w zarządzaniu rozwiązania.
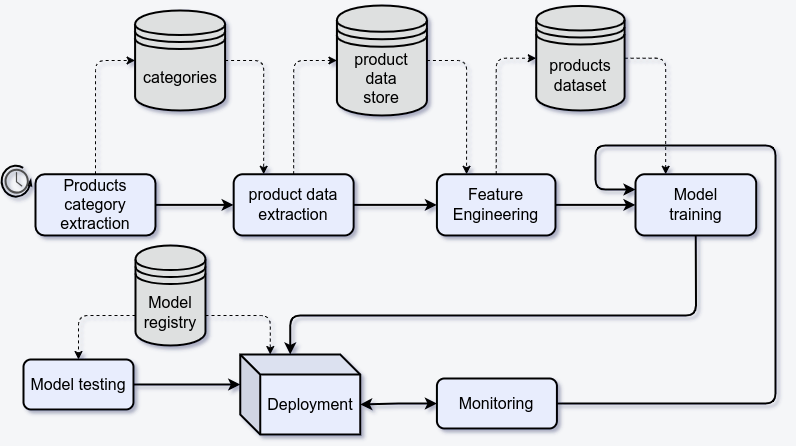
Architektura Orkiestracji Modelu
Architektura systemu składa się z kilku modułów, które często pojawiają się w projektach MLOps:
- Pozyskiwanie danych
- Przygotowywanie danych
- Trening modeli
- Wdrożenie (deployment)
- Monitoring
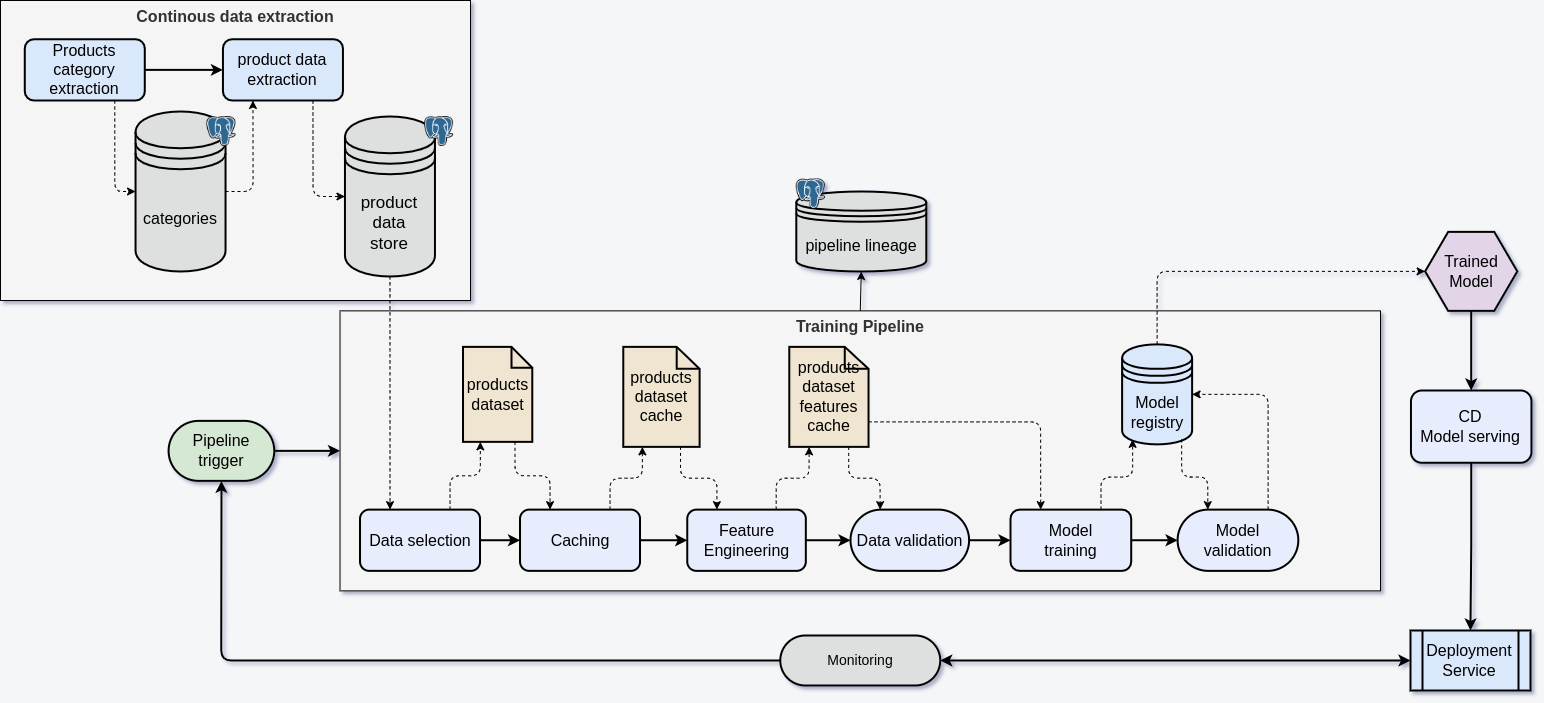
Pozyskiwanie Danych
Pozyskiwanie danych rozpoczynamy od ustalenia struktury drzewa kategorii dla każdego sklepu. Dzięki regularnym aktualizacjom drzewa możemy monitorować postęp w pozyskiwaniu danych oraz śledzić daty ostatnich zmian dla każdej kategorii. Aby zapewnić odpowiednią liczbę danych do treningu modelu, pobieramy co najmniej 2000 produktów przypisanych do każdej kategorii.
Przygotowywanie Danych
W przypadku naszego projektu dane treningowe nie wymagały intensywnej obróbki. Pipeline koncentruje się na stworzeniu zestawu danych treningowych i przeliczeniu wektorowych reprezentacji nazw produktów, co przyspiesza proces trenowania modeli, eliminując konieczność ponownego przeliczania tych wektorów w trakcie treningu.
Konteneryzacja
Konteneryzacja odgrywa kluczową rolę w całym pipeline’ie. Zadania dzielimy na mniejsze, które uruchamiamy wna workerach Airflow za pomocą PythonOperator, oraz większe, takie jak pozyskiwanie danych i trening modeli, które uruchamiamy jako kontenery Dockerowe przy użyciu DockerOperator.
Korzyści z Konteneryzacji
- Izolacja środowiska: Każde zadanie ma swoje własne zależności, co eliminuje problemy z kompatybilnością.
- Łatwość wdrażania: Kontenery mogą być uruchamiane na różnych maszynach, w tym na tych wyposażonych w GPU.
- Aktualizacje: Kontenery są automatycznie budowane w procesie CI (Continuous Integration) i ich najnowsze wersje są pobierane podczas uruchamiania w Airflow.
Dynamiczne Tworzenie Pipeline’ów
Pipeline dla pojedynczego marketplace’u jest gotowy, ale tworzenie pipeline’ów dla każdego nowego sklepu musi zostać zautomatyzowane, aby uniknąć ręcznej konfiguracji. Może to być istotne, gdy liczba sklepów rośnie do kilkudziesięciu lub setek.
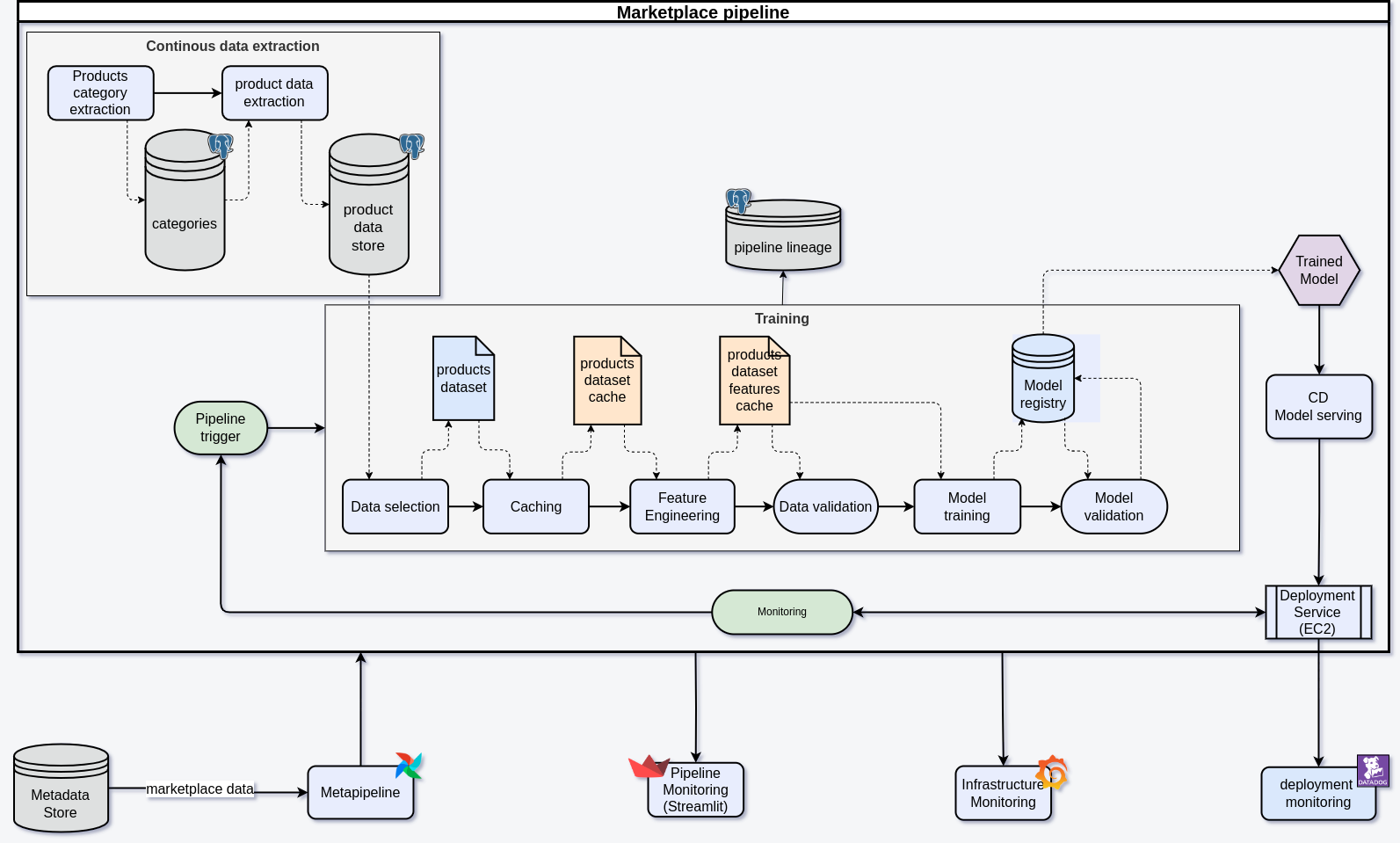
Konfiguracja Pipeline’ów
Konfiguracje pipeline’ów przechowujemy w rejestrze MLFlow. Specyficzne ustawienia dla każdego sklepu, takie jak źródła danych czy schemat bazy danych, są generowane dynamicznie. Na przykład dla Amazona konfiguracja zawiera szczegóły dotyczące źródła danych, komend do pobierania produktów i kategorii oraz harmonogram ich aktualizacji.
Po dodaniu takiej konfiguracji pipeline tworzony jest automatycznie i działa zgodnie z wyznaczonymi parametrami.

Ciągłe Pozyskiwanie Danych
Każdy sklep wymaga dedykowanego crawlera lub skryptu API do pobierania produktów. Kompleksowa automatyzacja tego procesu nie jest możliwa, ale wspólne biblioteki mogą ułatwić integrację z bazą danych. Crawlery muszą być niezawodne i skalowalne. Aby uniknąć długiego działania tasków, crawler może zostać przerwany i wznowiony bez utraty postępu. Co 6 godzin task crawlowania jest resetowany, co umożliwia regularne aktualizacje i lepsze zarządzanie logami.
Zarządzanie Bazą Danych
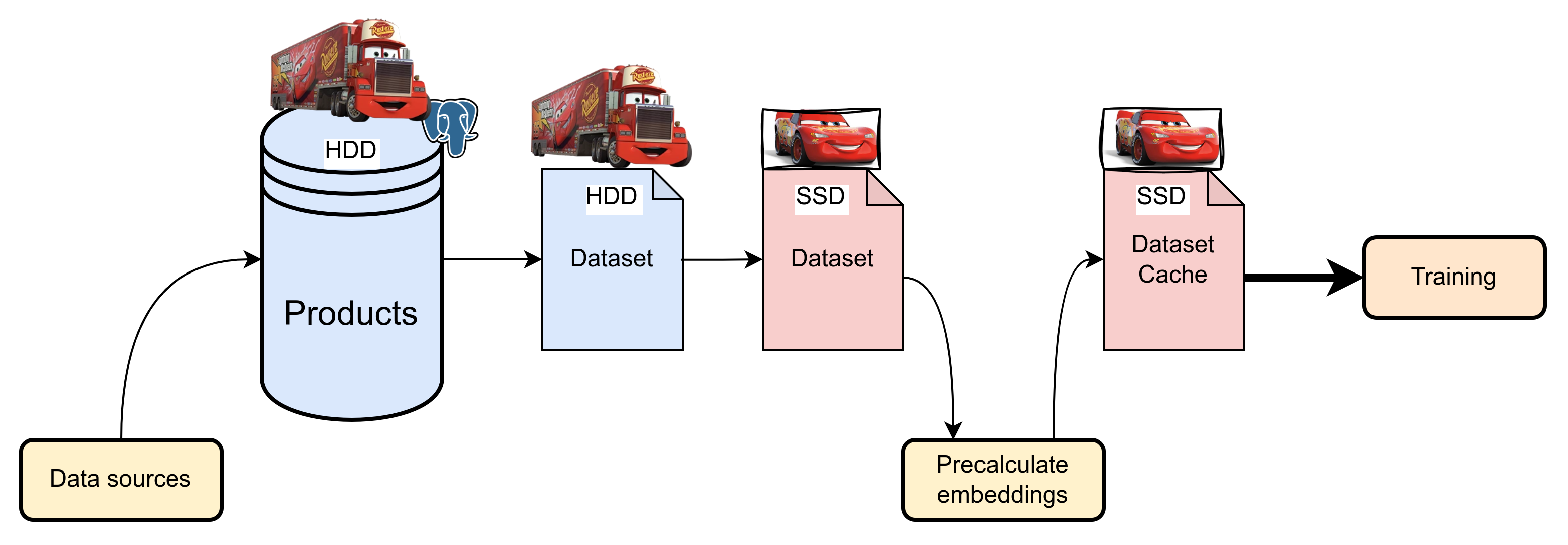
Efektywne zarządzanie dużymi zbiorami danych jest kluczowe dla wydajności systemu. Na początku używaliśmy szybkich dysków SSD do przechowywania i przetwarzania danych, co sprawdzało się dobrze mimo częstych operacji łączenia tabel. W miarę wzrostu zbiorów danych koszty SSD stały się jednak znaczące.
Próby korzystania z dysków HDD ujawniły problemy z niską liczbą operacji na sekundę (IOPS), co znacząco spowalniało pipeline.
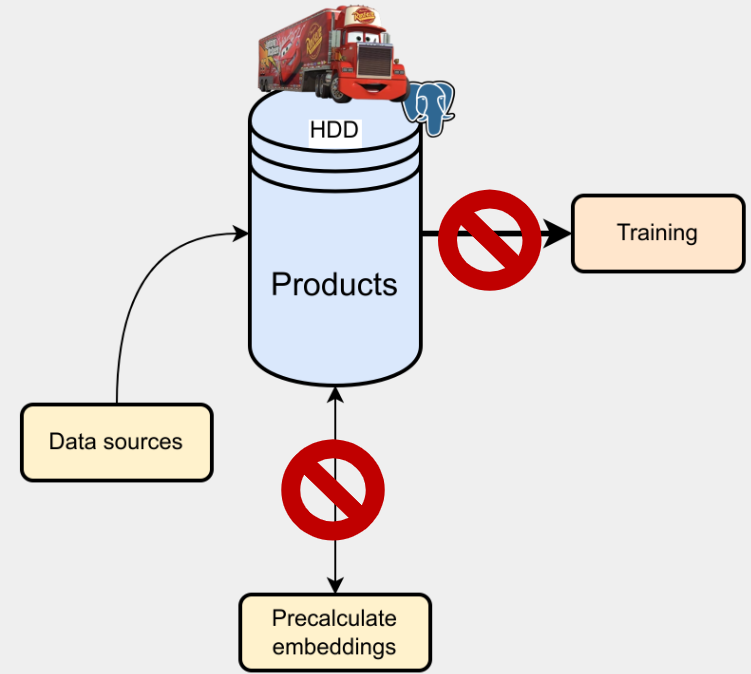
Z tego powodu przyjęliśmy podejście wielopoziomowe: dane bieżące i cache przechowujemy na szybkich dyskach SSD, a dane historyczne na tańszych, pojemnych HDD.
Podsumowanie
Tworzenie dużych, skalowalnych systemów wiąże się z wieloma wyzwaniami, jednak kluczowe jest automatyzowanie i izolowanie zadań, co pozwala zespołom skoncentrować się na rozwoju systemu zamiast na ręcznym zarządzaniu infrastrukturą. Dzięki konteneryzacji, rejestrom kontenerów oraz procesom CI/CD (Continuous Integration/Continuous Deployment) możemy uprościć wdrożenie i utrzymanie systemu. Odpowiednia architektura danych i sprzętu, zaplanowana na wczesnym etapie, jest niezbędna, aby zapewnić optymalną wydajność i skalowalność w miarę rozwoju projektu.


