


W szybko rozwijającym się świecie sztucznej inteligencji postęp od GPT-3 do rewolucyjnego Chat-GPT stanowił przełomowy skok. Choć oba modele pozostawiły głęboki ślad w dziedzinie, interesujące jest zagłębienie się w niuanse, które je rozróżniają, i ustalenie, czy Chat-GPT to ulepszona wersja wcześniejszego modelu czy może zupełnie nowy i osobny byt. W tym artykule przedstawimy rolę dużych modeli językowych (Large Language Models - LLM) oraz rolę uczenia ze wzmocnieniem (Reinforcement Learning - RL) w kształtowaniu nowoczesnego rozwoju chatbotów, odkrywając złożone mechanizmy, które wypromowały te technologie jako aktualny symbol innowacji w sztucznej inteligencji.
Dlaczego poprzednie podejście nie są wystarczające?
Chociaż wcześniejsze metody tworzenia chatbotów, takie jak sequence-to-sequence (seq2seq), systemy oparte na regułach oraz modele oparte na odzyskiwaniu informacji (retrieval based models) w znacznym stopniu przyczyniły się do rozwoju sztucznej inteligencji konwersacyjnej, często nie spełniają oczekiwań pod względem dostarczania naturalnych, kontekstowych i ludzkich odpowiedzi. Tym podejściom zazwyczaj brakuję zdolności do zrozumienia skomplikowanych niuansów, zmiany kontekstu i generowania spójnego i adekwatnego dialogu, co skutkuje sztucznymi i mniej angażującymi interakcjami. Dodatkowo mają one trudności w: obsłudze pytań otwartych, zrozumieniu dwuznacznego języka czy dostosowaniu się do różnych stylów rozmowy, co ostatecznie ogranicza ich zdolność do zapewnienia płynnych, doświadczeń komunikacyjnych człowiek-komputer, które są coraz bardziej poszukiwane w dzisiejszym krajobrazie inteligentnych asystentów.
Co to uczenie przez wzmacnianie?
Uczenie przez wzmocnienie (RL) wyróżnia się spośród innych paradygmatów uczenia maszynowego ze względu na skupienie się na nauce poprzez interakcję z otoczeniem w celu osiągnięcia określonego celu. W przeciwieństwie do uczenia nadzorowanego, które polega na etykietowanych zestawach danych, algorytmy RL są zaprojektowane do podejmowania sekwencyjnych decyzji, maksymalizujących kumulatywną sumę nagród - podczas poruszania się w złożonych i niedeterministycznych środowiskach. To unikalne podejście umożliwia modelom RL uczenie się poprzez metodę prób i błędów, optymalizując przy tym procesy podejmowania decyzji oraz strategie długoterminowe na podstawie informacji zwrotnej otrzymywanej od otoczenia. W rezultacie RL znajduje zastosowanie w dynamicznych scenariuszach, gdzie agent musi nieustannie dostosowywać się do zmieniającego się otoczenia, przez co jest to popularna metoda w dziedzinach takich jak robotyka, gry komputerowe oraz systemy autonomiczne, ale ostatnio znalazło ono nowe zastosowanie w “dostrajaniu” dużych modeli językowych.
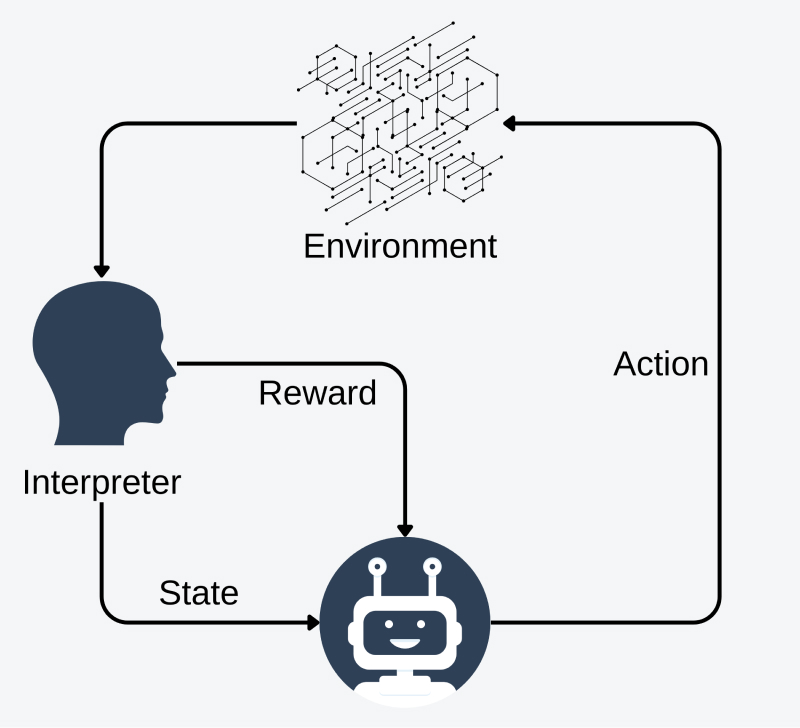
Reinforcement Learning from Human Feedback (RLHF) - jak to działa?
RLHF działa poprzez włączenie ludzkiej informacji zwrotnej do procesu uczenia ze wzmanianiem, wykorzystując oceny lub demonstracje dostarczone przez ludzi, aby kierować trajektorią uczenia sztucznej inteligencji. Poprzez kombinację informacji zwrotnej od ludzi i eksploracji metodą prób i błędów, RLHF umożliwia agentowi bardziej efektywne uczenie się skomplikowanych zadań, które są trudne do zdefiniowania przy czym redukuję dystans między ludzką intuicją a zdolnościami uczenia maszynowego. W przetwarzaniu języka naturalnego te skomplikowane zadania mogą obejmować zrozumienie komedii, uprzejmości itp. Aby zastosować RLHF do dużych modeli językowych, musimy podzielić ten proces na trzy główne kroki:
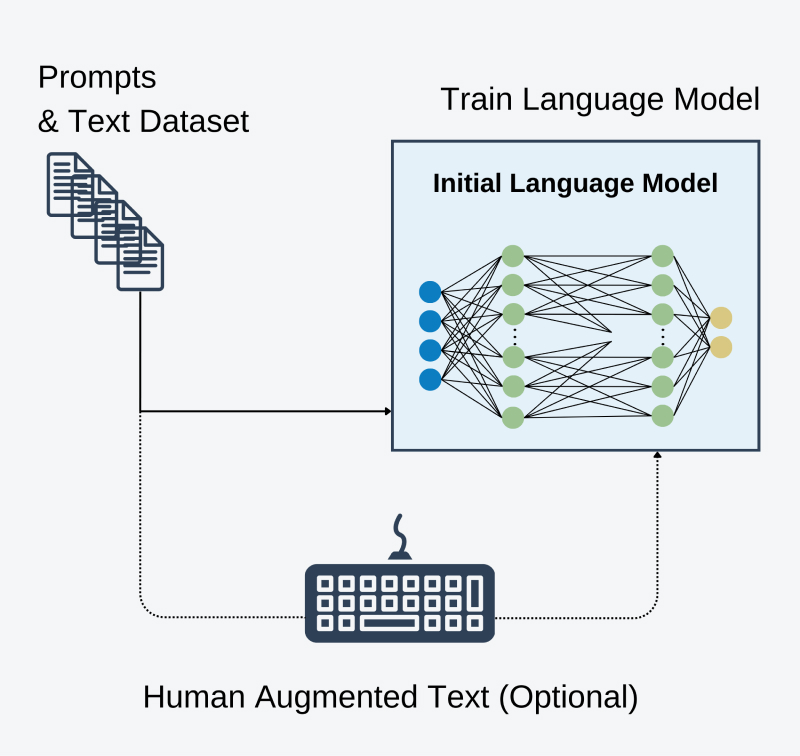
- Pre-Trenowanie modelu językowego przy użyciu standardowej procedury autoregresyjnej.
Jest to standardowa procedura uczenia dużego modelu językowego, gdy ma być on wykorzystany do generowania kolejnych tokenów na podstawie już wcześniej widzianych. Ten krok jest opcjonalny, ponieważ obecnie wiele otwartych dużych modeli językowych jest trenowanych na zbiorach danych tak dużych, że już widziały wystarczająco wiele przykładów rozmów, dodatkowo posiadając głębokie zrozumienie języka ludzkiego.
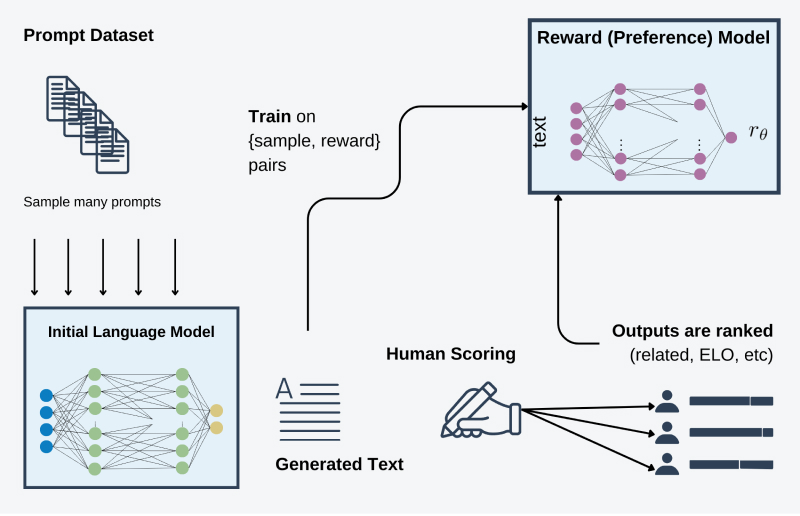
- Wytrenuj model nagród, wykorzystując oceny uzyskane od ludzkich ekspertów.
Aby umożliwić lepsze zrozumienie złożonych form językowych, takich jak humor czy metafory, ludzcy recenzenci oceniają odpowiedzi generowane przez wytrenowany generatywny model językowy, przypisując im odpowiednie oceny lub ustawiając odpowiedzi w rankingu (na przykład, można użyć modelu ELO). Ten proces pomaga ustanowić system porównawczy dla wszystkich odpowiedzi, umożliwiając modelowi przypisywanie nagród w kolejnych etapach. W rezultacie model jest skierowany do generowania odpowiedzi najwyższej jakości, wykorzystując nagrody pozyskiwane w trakcie tego procesu.
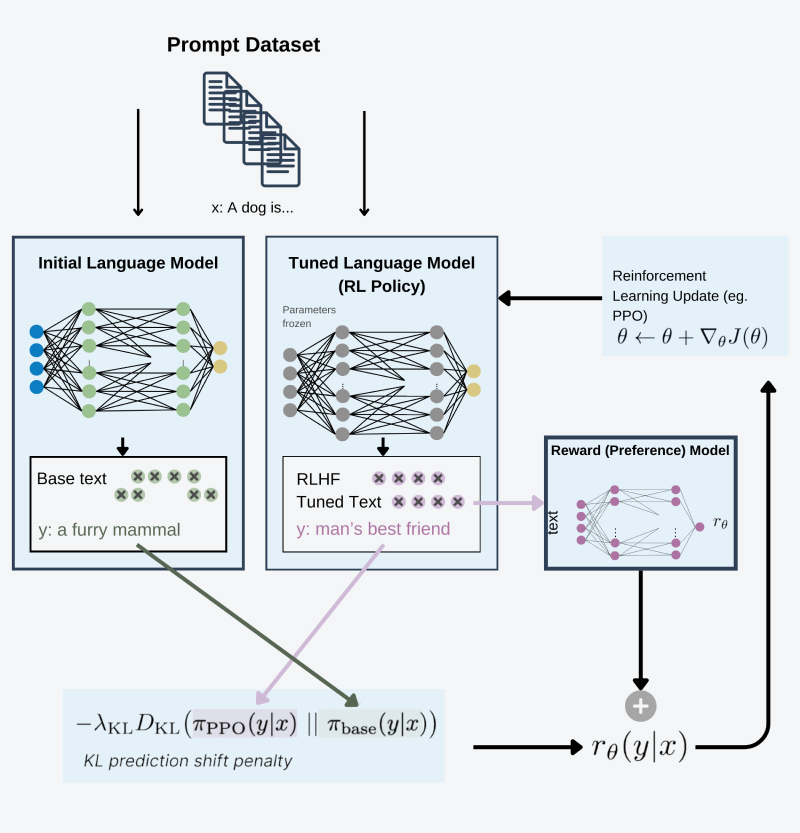
- Dostrój model wykorzystujące dynamikę RL’a, wykorzystując nagrody pobierane z wytrenowanego modelu z poprzedniego etapu.
Aby ograniczyć model przed wykorzystywaniem mechaniki RL’a i uczenia się wytwarzania bezwartościowych odpowiedzi w celu maksymalizacji nagród, utrzymujemy dwie wersje dużego modelu językowego. Dzięki temu zachowujemy całą istniejącą wiedzę modelu i jego zrozumienie języka ludzkiego. Jedna z wersji modelu ma zamrożone wagi, a podczas obliczania funkcji straty stosujemy dodatkową część odpowiedzialną za regularyzację (rozbieżność Kullbacka-Leiblera), który kontroluje, aby wagi nie zmieniały się za bardzo w porównaniu do oryginalnego modelu. Poza wykorzystaniem modelu nagród i procesu regularyzacji jest to w “przybliżeniu” standardowy eksperyment wykorzystujący uczeniem ze wzmacnianiem, gdzie przestrzeń akcji to tokeny z zasobu słownika modelu, a przestrzeń stanów to rozkład możliwych tokenów wejściowych.
Czy RLHF może być wykorzystany do innych zadań?
RLHF, pierwotnie stosowana w zadaniach takich jak robotyka, przewyższa duże modele językowe.
Ostatnio badacze z Nvidia wykorzystali ten proces do nauczania modelu MineCLIP na zadaniach z gry Minecraft. Gdzie jest to gra z otwartym światem oraz ze złożoną mechaniką rzemiosła, budowy i eksploracjii. Kolekcja zadań obejmuje szeroki zakres wyzwań od bardzo prostych, takich jak wyposażanie zadanego przedmiotu, aż po budowę skomplikowanych struktur, itp. Pierwszy etap polega na tworzeniu specjalistycznego zbioru danych. Do tego celu używane są filmy pobrane z YouTube z audiodeskrypcją audio. Następnie ekspert ludzki jest wykorzystywany do odpowiedniego oceniania spisanej transkrypcji, co pozwala na zebranie wielu zadań z właściwie ocenionym opisem.
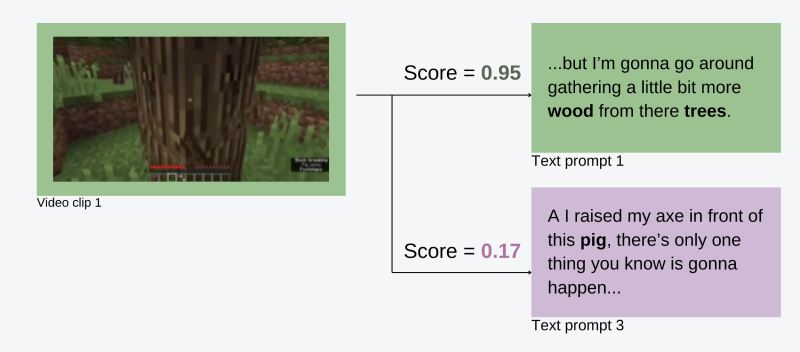
Następnie wykorzystując zebrany zbiór danych, dostosowujemy model wielomodalny, łączący filmy i tekst. W rezultacie otrzymujemy model, który informuje nas, jak dobrze określony ciąg klatek stworzony podczas rozgrywki w Minecraft jest opisany dostarczonym tekstem. Ten model jest równoważny modelowi nagród z procedury RLHF do dostrojenia modeli językowych. Następnie, dostarczając opis zadania i zbioru klatek z rozgrywki, możemy użyć powyższego modelu i standardowej procedury uczenia ze wzmocnieniem (uczenie się za pomocą nagród), aby stworzyć agenta zdolnego do rozwiązywania różnych zadań w Minecraft. Do poznania bardziej szczegółowego opisu gorąco polecam lekturę oryginalnej publikacji.
Podsumowanie:
RLHF to potężna metoda, która pomaga modelom językowym ze zdobyciem/utrwaleniem istotnej wiedzy dziedzinowej i lepiej zrozumieć skomplikowane tematy, które nie mogą być łatwo ujęte w formułach matematycznych. Istotne jest podkreślenie, że RLHF wymaga danych oznaczonych przez ekspertów, co ogranicza jego dostępność. Realizacja tego procesu zwykle wymaga znacznego budżetu lub zaangażowania społeczności w zbieranie danych.
Analiza różnic między ChatGPT a GPT-3 ujawnia, że są to modele podobne, ale z istotnymi udoskonaleniami Chat'aGPT. To ten sam model; jednak jego osiągi w konwersacjach zostały znacząco zwiększone dzięki dostrojeniu procedurą RLHF.


