


Modele zero-shot są pomocne przy prototypowaniu projektów z zakresu uczenia maszynowego, ponieważ z reguły nie potrzebują dodatkowego treningu do działania. Szczególnie dobrze radzi sobie CLIP - popularny model od OpenAI.
Jak działa CLIP
CLIP (Contrastive Language–Image Pre-training) to model zero-shot wypuszczony przez OpenAI na początku 2021 roku. Jest on wytrenowany na różnorodnych parach obrazek-tekst, przez co skutecznie uczy się koncepcji wizualnych za pośrednictwem języka naturalnego.
CLIP jest bardzo elastycznym i łatwym w konfiguracji modelem, który ma wszechstronne zastosowania.
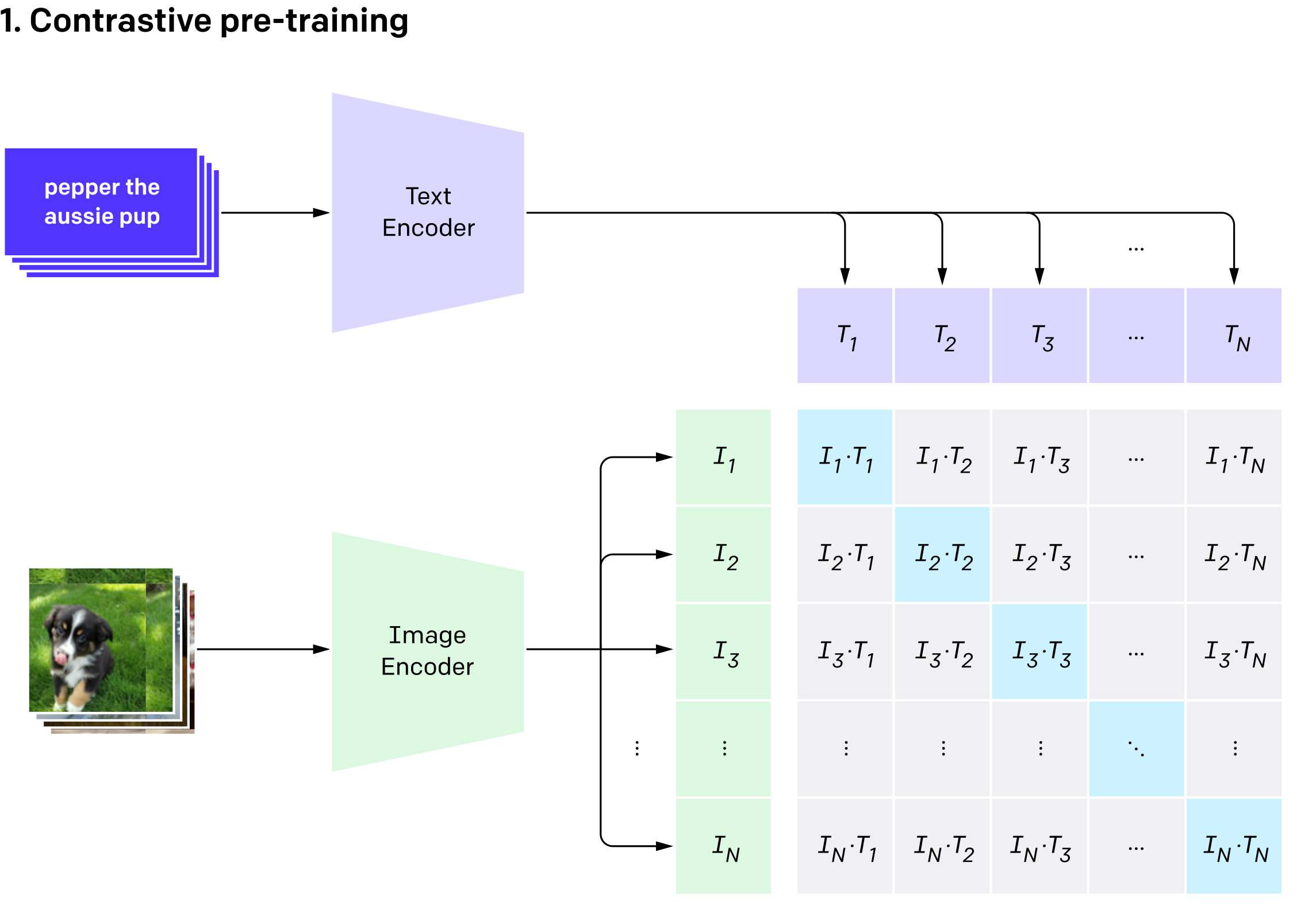
CLIP składa się z dwóch części: Image Encodera (którym może być przykładowo ResNet albo Vision Transformer) i Text Encodera (model bazujący na Transformerze). Oba te modele zwracają wektory zawierające zaenkodowaną reprezentację danego obrazka oraz tekstu. Wektory te są następnie porównywana za pomocą podobieństwa cosinusowego - im większa wartość, tym bardziej obrazek i tekst są do siebie podobne.
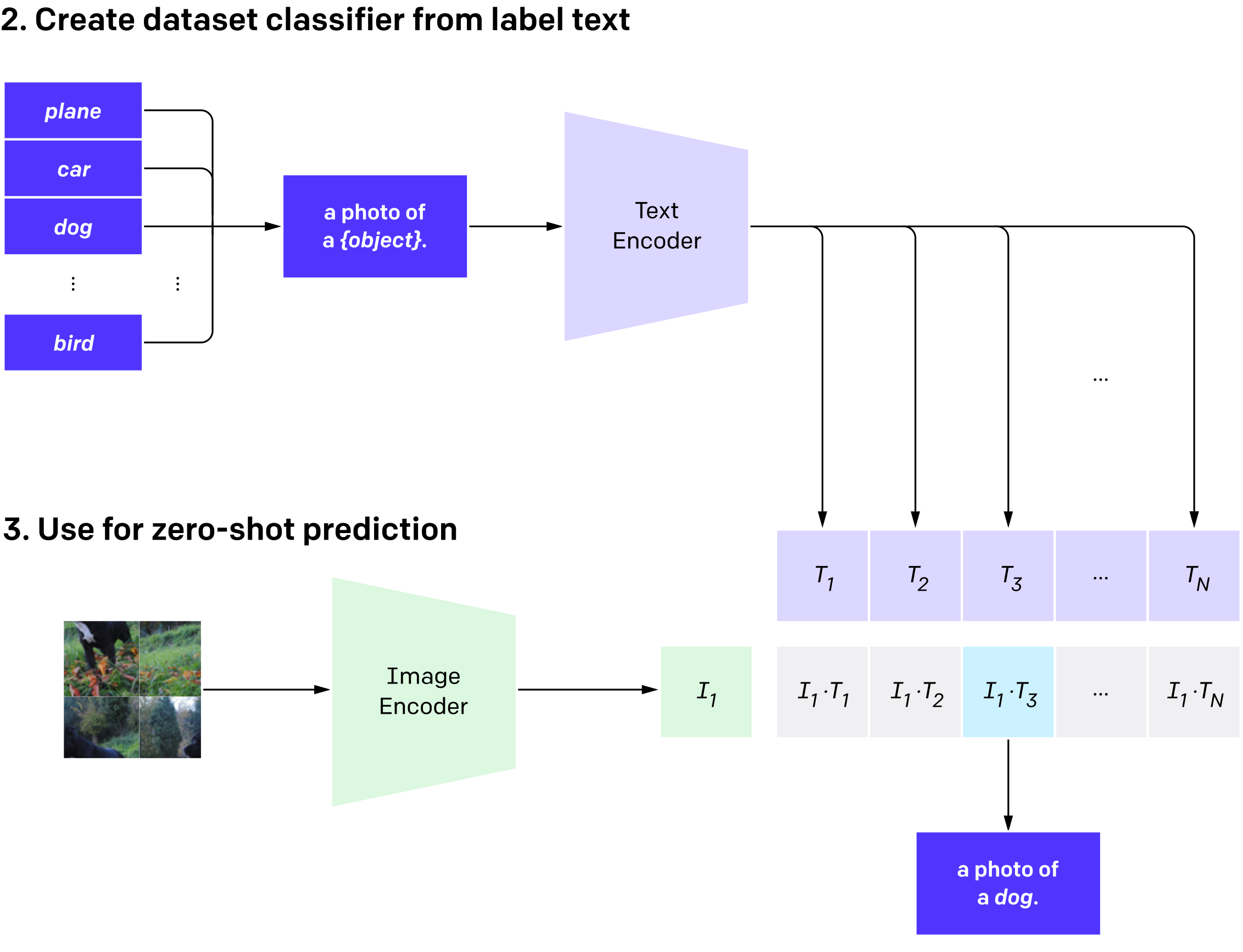
CLIP może być zastosowany do dowolnego zadania klasyfikacji z zakresu wizji komputerowej, poprzez podanie nazw kategorii, które mają być rozpoznane. Wystarczy przygotować zbiór kategorii i dla każdej stworzyć jej reprezentację za pomocą Text Encodera. Następnie każdy obrazek wrzucony zostaje do Image Encodera, a jego wyjściowy wektor porównywany jest z każdym z testowych wektorów. Jako przewidywaną kategorię wybieramy tę, do której wektor obrazka jest najbardziej “podobny”.
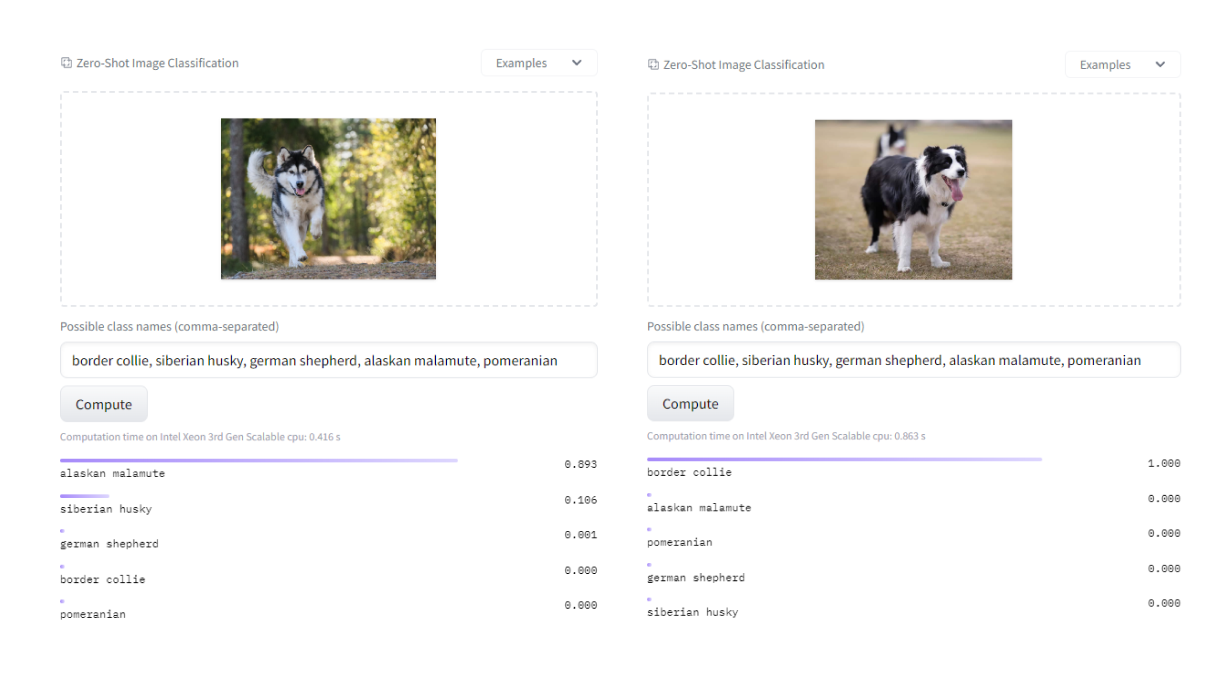
Przykładowe działanie CLIP. Wartości po prawej stronie są dodatkowo przepuszczone przez softmax, co upodabnia działania modeli do klasycznej klasyfikacji.
CLIP i prototypowanie
Dzięki swojej elastyczności i wszechstronności, CLIP może zostać wykorzystany do szybkiego prototypowania projektów z zakresu wizji komputerowej, bez potrzeby dodatkowych danych treningowych. Załóżmy, że potrzebujemy modelu rozpoznającego na wideo konkretną rasę psa, np. Border Collie.
Najprostszym podejściem będzie porównywanie podobieństwa (Cs) pomiędzy klatką wideo (x), a docelowym promptem tj. “border collie” (yp). Jeżeli podobieństwo jest wyższe od jakiegoś zdefiniowanego progu (threshold), uznajemy obecność psa na obrazku.
Matematycznie będzie to zdefiniowane w ten sposób:
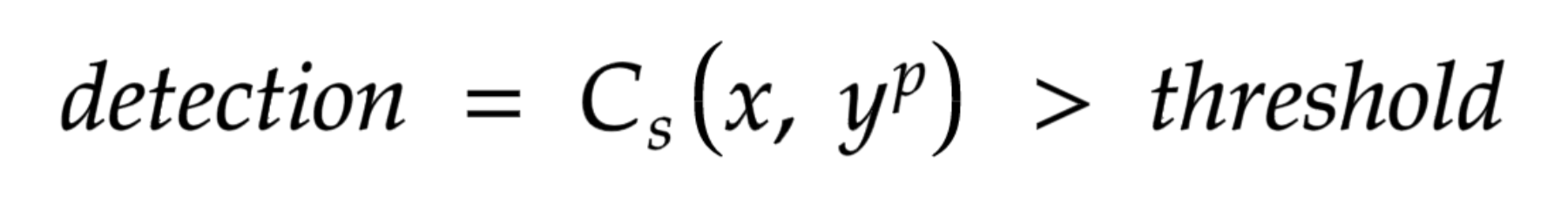
Jak widać CLIP bardzo sprawnie poradził sobie z detekcją:

Niestety, użycie samego docelowego prompta może powodować częste pojawianie się predykcji false positive - jako że działamy na wartości podobieństwa pomiędzy obrazkiem, a tekstem, inne psy mogą być wizualnie podobne do naszej docelowej rasy.

Żeby temu zapobiec, możemy wprowadzić bardziej skomplikowany warunek, opierający się na promptach “negatywnych” (Yn), to znaczy na zbiorze “kategorii”, których nie chcemy rozpoznawać - w naszym przypadku będzie to zbiór pozostałych ras psów np. siberian husky, alaskan malamute, itp. Wprowadzając ten zbiór, oczekujemy, że nasza docelowa klasa, będzie miała większą wartość podobieństwa z obrazkiem, niż pozostałe “negatywne” prompty. Matematycznie ten warunek prezentuje się następująco:
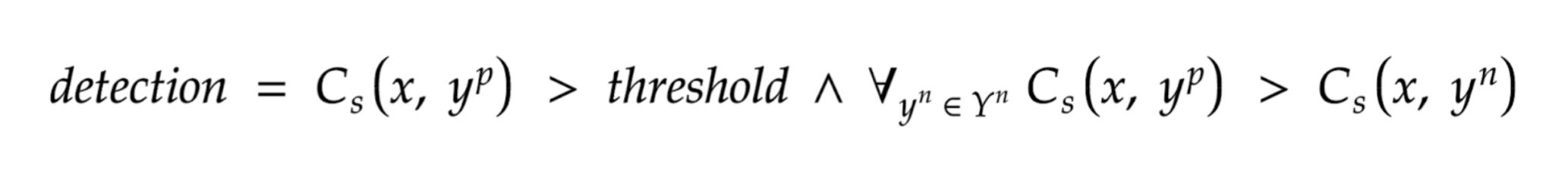


Jak widać na powyższych przykładach, ilości predykcji false positive zostały znacznie ograniczone, a sama predykcja psa border collie nie ucierpiała na wprowadzeniu dodatkowego warunku.
Prompt engineering
Dzięki elastyczności CLIPa nie jesteśmy ograniczeni do prostego prompta w stylu “border collie”, ale możemy przeprowadzać eksperymenty z różnymi konfiguracjami słów, znajdując te, które są optymalne dla naszej sytuacji.
Przykładowo, zamiast pisać po prostu “border collie”, możemy też użyć:
- an image of a border collie, a dog breed
- border collie, a dog breed
- a picture of a dog, a border collie breed
- etc.

Na powyższym wykresie widać, że wartości podobieństwa są podobne dla wszystkich promptów, ponieważ kontekstowo oznaczają to samo. CLIP daje nam praktycznie nieograniczone możliwości w formowaniu tekstów opisujących obrazek, dzięki czemu możemy formować prompty zawierające dodatkowe warunki np. “border collie with brown and white hair”
Ograniczenia CLIP
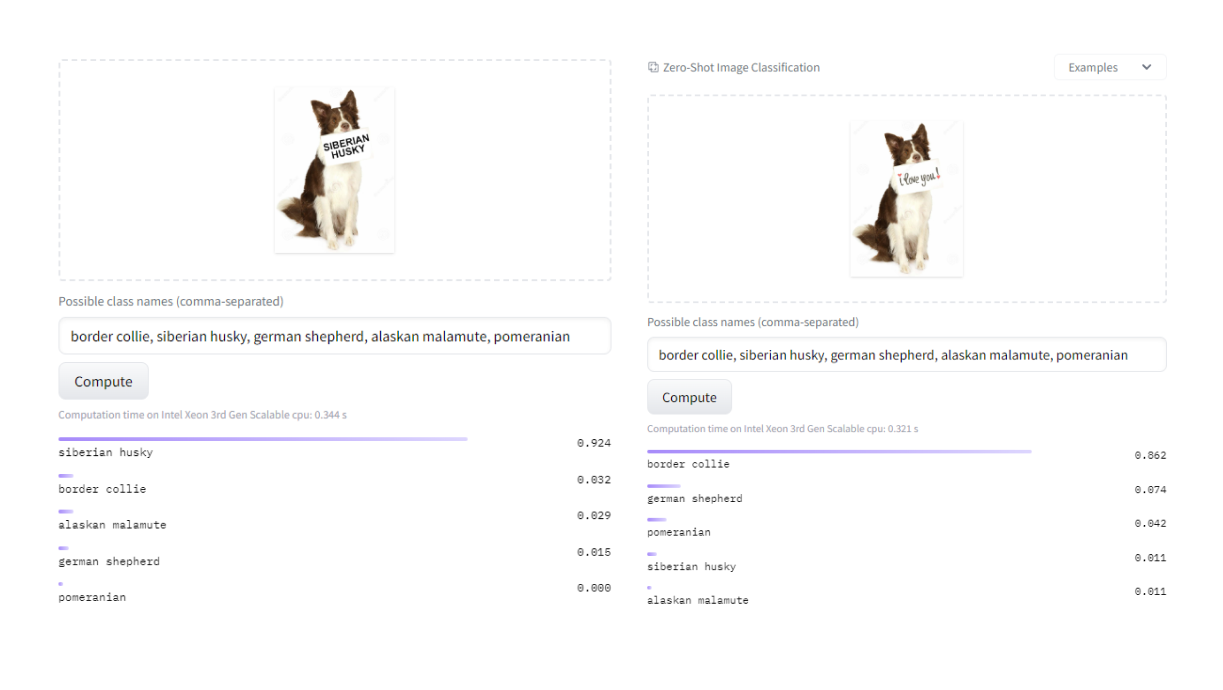
Oprócz swoich zalet, CLIP posiada też parę ograniczeń, na które trzeba uważać podczas tworzenia prototypów. Przykładowo CLIP wrażliwy jest na obecność tekstu na obrazku. Model skupi się na nim zamiast na zawartości obrazka, co może spowodować błędną predykcję.
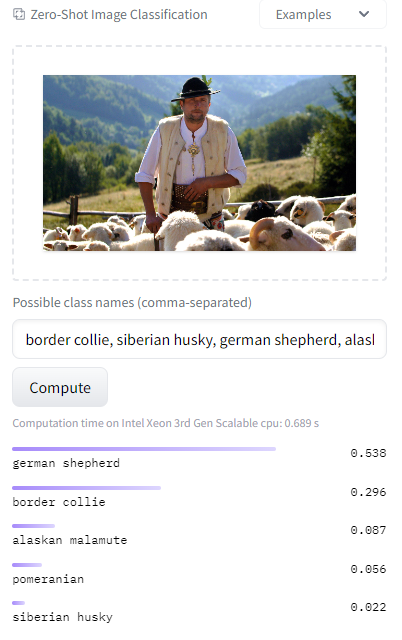
Kolejnym, z przykładowych problemów, są różne znaczenia słów, które mogą zmylić model. CLIP uczy się na postawie zdjęć sparowanych z podpisami, więc całkowicie różne od siebie obrazki z podobnymi słowami w opisie, mogą być dla CLIPa podobne. Często może się to dziać dla różnych marek bądź nazw własnych jak np. rasy psa. Przykładowo możemy przypadkowo wykrywać owczarki niemieckie, jeśli na obrazku pojawi się ludzki pasterz, czyli “shepherd”
Podsumowanie
CLIP to model zero-shot stworzony przez OpenAI, który jest bardzo elastyczny i uniwersalny. Z najważniejszych zalet CLIP możemy wyróżnić:
- Szybkie prototypowanie projektów z zakresu wizji komputerowej bez potrzeby dodatkowych danych treningowych
- dużą elastyczność w formowaniu tekstów opisujących obrazki
Jednakże CLIP mimo swojej uniwersalności posiada też pewne ograniczenia, na które trzeba uważać podczas tworzenia prototypów, takie jak:
- wrażliwość na obecność tekstu na obrazku
- różne znaczenia słów, co może wpłynąć na błędną predykcję.
Jeśli interesuje Cię implementacja rozwiązań opartych o wizję komputerową oraz przetwarzanie języka naturalnego to koniecznie napisz do nas.


