


Rozpoznawanie mowy jest powszechne we współczesnym świecie technologii - asystenci głosowi, umożliwiający wybieranie numerów w trybie głośnomówiącym dla użytkowników smartfonów (pomocne dla kierowców), sterowanie głosem w samochodowych modułach infotainment, wyszukiwanie głosowe - wszystkie te urządzenia posiadają automatyczne rozpoznawanie mowy jako rdzeń swoich funkcjonalności.
Co to jest ASR?
To proces pozyskiwania transkrybowanego zdania z próbki mowy. Dzięki niemu użytkownik może komunikować się z komputerem w najbardziej naturalny, ludzki sposób - po prostu nagrywając wypowiedź i wysyłając ją do algorytmu, który przetworzy fale akustyczne w celu przetłumaczenia zdania z formatu werbalnego na tekstowy.
Można zadać sobie pytanie, czy takie systemy są nam potrzebne i czy w ogóle są przydatne - zastosowanie systemów automatycznego rozpoznawania mowy pozwala osobom z różnymi niepełnosprawnościami fizycznymi na swobodną obsługę aplikacji: nie zawsze mogąc wprowadzić tekst ręcznie, użytkownik może werbalnie wejść w interakcję z systemem - analogiczna sytuacja ma miejsce, gdy kierowca obsługuje system rozrywki za pomocą komend głosowych: nie musi zdejmować rąk z kierownicy, aby zmienić stację radiową, odebrać telefon czy wyznaczyć trasę w systemie nawigacji.
Jak tworzymy rozwiązania ASR?
Stworzenie systemu rozpoznawania mowy w konwencjonalny, deterministyczny sposób jest ogromnym zadaniem - algorytm musiałby rozpoznać zwykle ponad sto tysięcy słów: Język angielski ma około 170 000 słów w bieżącym użyciu, języki takie jak chiński jeszcze więcej, co prowadzi nas do wniosku, że klasyczne podejście do tworzenia takiego systemu jest niewystarczające.
Wątpliwości te można rozwiązać poprzez zastosowanie uczenia maszynowego - stworzenie rozwiązania opartego na SI jest korzystne zarówno pod względem dokładności, jak i rozwoju: trenowanie modelu na odpowiedniej ilości danych jest łatwiejsze do wykonania, a później, na etapie wdrożenia, istnieją już dojrzałe narzędzia pozwalające na wnioskowanie na modelu w środowisku produkcyjnym.
Proces tworzenia systemu automatycznego rozpoznawania mowy polega głównie na pozyskaniu odpowiedniej ilości próbek głosu o wymaganej jakości i wykorzystaniu ich jako danych treningowych dla modelu sztucznej inteligencji. I to jest właśnie ten punkt, który sprawia najwięcej kłopotów - trening modelu uczenia maszynowego wymaga danych. Dużo. Jeśli chcemy mieć dokładny, uniwersalny model, 10 godzin nagranych próbek mowy to za mało, nawet 100 godzin niewiele znaczy dla modelu - jeden z najlepiej działających modeli dla języka angielskiego był trenowany na ponad 30 000 godzin próbek głosu!

Kolejną kwestią jest dostępność danych - język angielski jest lingua franca współczesnego świata, dlatego też możemy znaleźć wiele anotowanych zbiorów danych w tym języku, które są ogólnodostępne w Internecie. Problem pojawia się w przypadku innych języków, które zazwyczaj nie posiadają tak dużych zbiorów próbek mowy - zebranie wystarczająco dużego zbioru danych do wytrenowania modelu może być dość czasochłonne.
Przykład - transkrypcja mowy na tekst w języku arabskim
W Numlabs próbowaliśmy podejść do rozpoznawania mowy tworząc system transkrypcji mowy na tekst w języku arabskim. W naszym przypadku, do budowy modelu wykorzystaliśmy Mozilla DeepSpeech, open-source'owy silnik do rozpoznawania mowy. Rdzeń tego silnika opiera się na technikach przedstawionych w pracy badawczej Baidu Deep Speech. Pozwala on na wytrenowanie modelu dla dowolnego języka, wymagając jedynie zbioru danych oraz pliku tekstowego z literami występującymi w transkrypcji.
Bazą danych użytą do treningu jest Mozilla Common Voice - open-source'owa biblioteka baz danych, zawierająca próbki mowy z różnych języków, które są anotowane przez członków społeczności. W przypadku języka arabskiego jest to 49 godzin zweryfikowanych próbek mowy - wydaje się to niewystarczającą ilością, ale spróbujmy, jak dokładny będzie model przy tak ograniczonych zasobach. Aby pokazać, jak ważne jest posiadanie jak największej ilości próbek mowy, wytrenowaliśmy 3 modele: jeden z dziesiątą częścią oryginalnego zbioru danych, drugi z połową zbioru danych, a ostatni używał wszystkich próbek do treningu. Wyniki są przedstawione na histogramie poniżej:
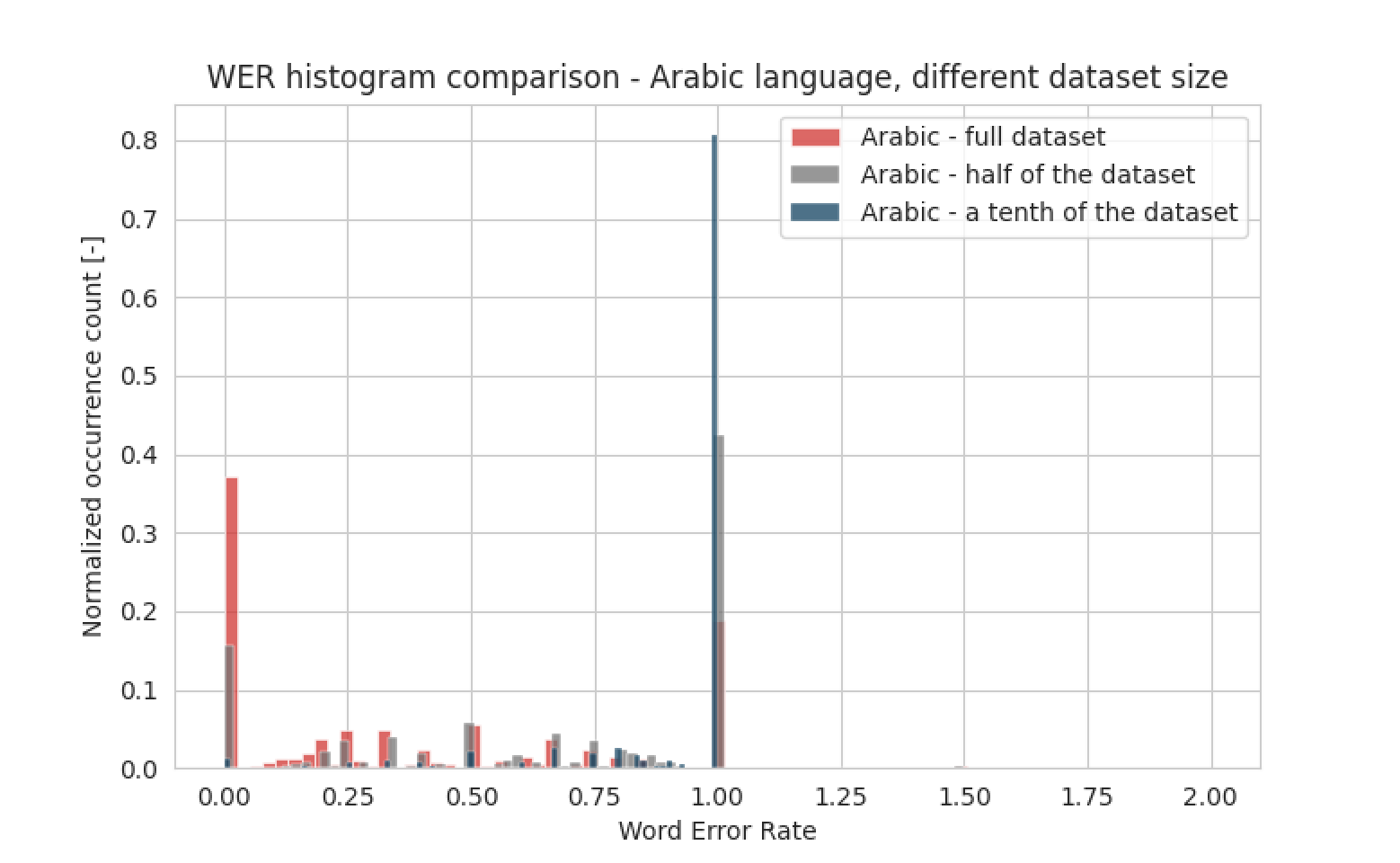
Widzimy wyraźnie, że im więcej próbek, tym lepsze wyniki. Model nigdy nie osiągnie dokładności na poziomie 100%, ale możliwe jest osiągnięcie poziomu ponad 90%, pod warunkiem posiadania wystarczająco dużego zbioru danych.
Wydajność człowieka kontra AI
Teraz mamy już wytrenowany model dla języka arabskiego. Ale czy naprawdę konieczne było opracowanie rozwiązania opartego na sztucznej inteligencji? Jak w takim zadaniu poradziłby sobie człowiek? Badania nad porównaniem wydajności człowieka z algorytmem zostały przeprowadzone w Microsofcie, a ich wyniki przedstawiono w dokumencie. Stwierdzono w nim, że dokładność dla starannej ludzkiej transkrypcji wynosi od 95,5 do 95,9%, podczas gdy szybka transkrypcja obniża ją do 90,4%. Staranna transkrypcja zajmuje zwykle dużo czasu, czasem nawet wiele przesłuchań, podczas gdy użytkownik często żąda jak najszybszych wyników. Rozwiązania oparte na sztucznej inteligencji pozwalają nam przetwarzać mowę szybciej niż człowiek, zachowując przy tym wyższą dokładność - najnowocześniejsze modele osiągają dokładność ponad 98%!
Podsumowanie
Powyższy artykuł daje pojęcie o automatycznym rozpoznawaniu mowy - czym jest, po co go używać, jak go tworzyć i najważniejsze - jak sprawić, aby działał. Jest to tylko wprowadzenie do tematu, w następnym artykule pokażemy bardziej techniczne podejście, z opisem struktury modelu i pokazaniem perspektyw rozwoju - bo jest tu jeszcze wiele do odkrycia.


