


W tym wpisie poruszymy temat oceny jakości klasyfikatorów. Na początku zdefiniujemy samo pojęcie klasyfikacji. Następnie od zera wyprowadzimy najpopularniejsze miary jakości i bazując na przykładach będziemy chcieli wyrobić intuicje w temacie używania konkretnych współczynników.
Wprowadzenie
Człowiek aby opisać zachodzące zjawiska i istniejące przedmioty posługuje się modelami. Z fizyki znamy na przykład drugie prawo dynamiki Newtona opisujące przyczynę ruchu czy bryłę sztywną - model idealnego ciała stałego. Wiemy, że akceptowalnie opisują świat tylko w pewnych warunkach. Te proste przykłady ilustrują nam, że modele w zależności od warunków działają "lepiej" lub "gorzej". Jednakże aby wydać osąd o ich jakości musimy wybrać jakieś kryterium według którego je ocenimy. Podobnie sprawa ma się w Data Science. Na podstawie danych tworzymy modele. Zanim jednak do tego przystąpimy powinniśmy zastanowić się nad tym co będzie miarą naszego sukcesu i nie jest to wcale tak oczywiste jak mogłoby się wydawać.
...modele w zależności od warunków działają "lepiej" lub "gorzej". Jednakże aby wydać osąd o ich jakości musimy wybrać jakieś kryterium według którego je ocenimy.
Zagadnienie klasyfikacji
W pierwszym artykule z tego cyklu przyjrzymy się problemowi klasyfikacji binarnej. Metody opisane poniżej można jednak w prosty sposób uogólnić na klasyfikację na większą ilość klas.
O problemie klasyfikacji mówimy kiedy chcemy przydzielić element do jednej z predefiniowanych klas. Przykładem może być oddzielenie produktów wadliwych od poprawnie wykonanych albo przydzielenie emaili do odpowiedniej wcześniej ustalonej zakładki. Innym bardziej rozbudowanym, jest problem przedstawiony na obrazku poniżej. Nasz algorytm ocenia co przedstawiono na obrazku i przypisuje mu jedną z dziesięciu kategorii. Dalej jest to klasyfikacja, ale już nie binarna. Zagadnienie to możemy oczywiście zamienić na dziesięć problemów binarnych typu: czy na obrazku jest samolot? (tak/nie), czy na obrazku jest samochód (tak/nie) etc.
 CIFAR-10 popularny zbiór do testowania algorytmów klasyfikacji
CIFAR-10 popularny zbiór do testowania algorytmów klasyfikacji
Błędy klasyfikacji i confusion matrix
Pomyślmy o problemie klasyfikacji klienta od dwóch grup: klient wróci i kupi kolejny produkt lub zrezygnuje z naszych usług. Jest oczywicie klasyfikacja binarna, czyli “obiekty” w tym przypadku klientów dzielimy na dwie wzajemnie rozłączne i dopełniające się grupy.
Jest to może nieco nieintuicyjne ale, są aż cztery możliwe wyniki klasyfikacji przeprowadzonej przez model. Dwa pierwsze to poprawna klasyfikacja - algorytm stwierdzi, że klient powróci i rzeczywiście tak się stanie (TP - True Positive) oraz klient nie powróci co poprawnie przewidział algorytm (TN - True Negative). Oczywiście może również popełnić błąd - zaklasyfikować wiernego klienta do grupy która chce odejść (FN - False Negative) i vice versa (FP - False Positive).
Te cztery wartości zazwyczaj umieszcza się w tablicy nazywanej z angielskiego confusion matrix, lub po polsku tablicą pomyłek co przedstawiono poniżej na przykładzie algorytmu wykrywającego czy na przedstawionym mu zdjęciu znajduje się kot.
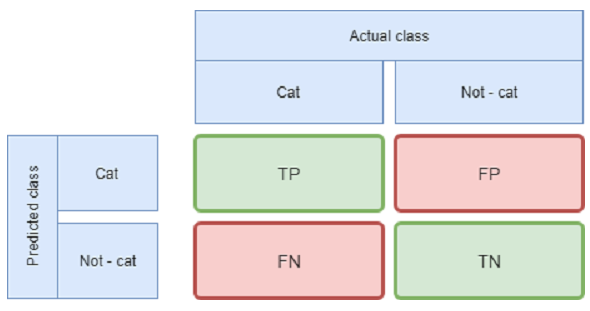
Kot czy nie kot? Przykład confusion matrix dla problemu wykrywania kotów
Rozróżnienie to na pierwszy rzut oka może wydawać się przerostem formy nad treścią jak przekonamy się dalej jest jednak bardzo pomocne. Rozważmy dwie firmy, pierwsza firma działa w branży która ma niewielu potencjalnych klientów. Druga ma wielu potencjalnych stałych klientów jednak zabiegi marketingowe są bardzo kosztowne. Właściciel pierwszej z nich woli więc zminimalizować błąd polegającym na odrzuceniu wiernego klienta (FN), zgadzając się na koszta związane z działaniami marketingowymi skierowanymi do osób niezainteresowanych (FP). Drugi CEO wręcz przeciwnie, z uwagi na wysokie koszta pozyskania klienta woli pewne inwestycje, nawet za cenę stracenia kilku potencjalnych kontraktów. Mam nadzieję, że przykład ten przekonał Cię do tego że, błąd błędowi nie równy i nawet jeśli się mylimy to zazwyczaj wolimy pomylić się w którymś z kierunków.
...błąd błędowi nie równy i nawet jeśli się mylimy to zazwyczaj wolimy pomylić się w którymś z kierunków.
Wskaźniki jakości
Niestety confusion matrix ma jedną wadę. Jest zestawem liczb. Dlaczego to wada? Ponieważ jak powiedziałby nie możemy powiedzieć że jedna tablica jest większa a więc “lepsza” niż druga, tak jak jedna liczba rzeczywista jest większa od drugiej. Dochodzimy więc do clue tego wpisu. Aby porównywać między sobą klasyfikatory tworzy się z elementów tablicy pewne współczynniki. Każdy z nich ma swoje wady i zalety. W dalszym ciągu przyjrzymy się kilku popularnym wartościom:
- Accuracy (dokładność)
- Recall (czułość)
- SPC (swoistość)
- Precision (precyzja)
Pierwszą miarą jest dokładność (accuracy). Zdefiniowana jest jako ilość poprawnie zaklasyfikowanych (zarówno TP i TN) próbek w stosunku do wszystkich. Wybierając więc model kierując się tym kryterium skupiamy się jedynie na tym ile próbek zostanie poprawnie sklasyfikowanych, tracimy informację o tym jaki typ błędu popełniamy. Na pierwszy rzut oka wydaje się to zawsze dobrym kryterium, nie zapominajmy jednak, że pewne pomyłki mogą być bardziej kosztowne od innych. Jak na przykład przy wydawaniu wyroków. Dodatkowo problem pojawia się przy niezbilansowanych zbiorach. Może okazać się, że model, który zawsze będzie wskazywał jeden typ odpowiedzi uzyska wysoką dokładność (accuracy) tylko dlatego, że zjawisko, które będziemy wykrywali występuje bardzo rzadko.
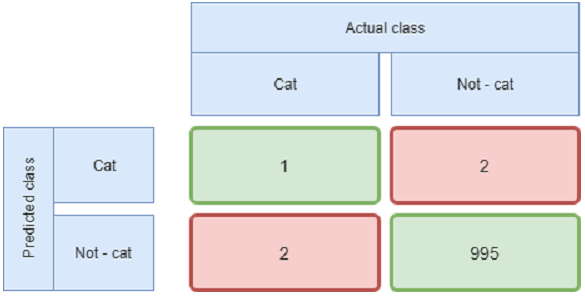
Przykład confusion matrix dla niezbilansowanego zbioru. Pomimo accuracy powyżej 99% algorytm bardzo słabo radzi sobie z wykrywaniem kota.
Jeśli za jakiś czas sztuczna inteligencja będzie wydawała wyroki sądowe, jestem przekonany że optymalizowana będzie przede wszystkim swoistość (SPC) sędziego. Co to oznacza? Jeżeli zakładamy, że wynikiem pozytywny jest to że osoba podejrzana jest rzeczywiście winna to SPC jest stosunkiem osób ilości uniewinnionych które rzeczywiście nie popełniły przestępstwa (TN) do wszystkich rzeczywiście niewinnych. Chcemy więc aby było jak najmniej niesłusznie skazanych. Stosując dokładność (accuracy) zamiast swoistości (SPC) tak samo traktowaliśmy osobę niesłusznie skazaną jak i tę której udało się uniknąć zasłużonej kary.
Precyzja (precision) byłby miarą zalecaną dla CEO drugiej firmy z drugiego rozdziału. Zależy mu na tym aby odezwać się tylko do klientów będących bardzo pewnymi kontrahentami. Możemy się więc już domyślić, że precyzja jest definiowana jako ilość próbek TP do sumy TP i FP. Staramy się więc minimalizować ilość klientów którzy z nami nie zostaną a zostali zaklasyfikowani jako długoterminowi kontraktorzy.
Na koniec czułość (recall), byłaby dobrym wskaźnikiem dla prezesa firmy pierwszej. Jest to stosunek TP do sumy TP i FN. Minimalizujemy więc ilość klientów odrzuconych jako nie wartych uwagi, którzy w rzeczywistości mogliby z nami współpracować.
Podsumowanie
We wpisie przestawiliśmy, na czym polega zagadnienie klasyfikacji. Następnie poznaliśmy rodzaje błędów pojawiających się w tego typu zagadnieniach. Bazując na tym wprowadziliśmy pojęcie confusion matrix. Poznaliśmy kilka miar jakości klasyfikatora i powedzieliśmy dlaczego ten a nie inny pasuje w podanym zastosowaniu. W tym momencie pojawia się pytanie, którego wskaźnika mam użyć w moim przypadku? W pierwszej kolejności należy zastanowić się co jest dla mnie wynikiem pozytywnym a co negatywnym. Kolejnym krokiem jest zinterpretowanie błędów FP i FN (zwanych także często błędem I i II rodzaju) w kategoriach biznesowych, czyli jakie tak naprawdę są konsekwencje popełnienia każdego z tych błędów. Następnie interpretujemy wzory opisujące współczynniki i wybieramy takie (liczba mnoga nie jest przypadkowa! Warto mieć na uwadze kilka wskaźników) które najlepiej pokrywają się z oczekiwaniami klienta. Poza wskaźnikami, polecam również przyglądaniu się confusion matrix, co cztery liczby to nie jedna.


