


W poprzednim artykule, dokonaliśmy wprowadzenia do tematu konwersji mowy na tekst: czym jest, jak powstaje, gdzie jest wykorzystywana. Teraz zanurzmy się głębiej w temat i spróbujmy zrozumieć logikę stojącą za tworzeniem i trenowaniem modelu dla naszego systemu automatycznego rozpoznawania mowy arabskiej.
Do budowy naszego modelu użyliśmy silnika Mozilla DeepSpeech - poza łatwością użycia, ma on jedną istotną zaletę - Mozilla oferuje wstępnie wytrenowany model angielski z WER 7.06%, który może być użyty jako baza do uczenia transferowego - dostosowywania wag w górnych warstwach z zachowaniem dolnych. Nasz zbiór danych to Mozilla Common Voice, zawierający 49 godzin transkrypcji próbek mowy o długości od 5 do 20 sekund. Jak zmierzyć dokładność.

Aby łatwo zmierzyć dokładność modelu, wprowadzono wskaźnik błędu słów (ang. word error rate, WER): opisuje on, ile słów w próbce zostało błędnie przepisanych - albo w słowie była literówka (substytucja), dodatkowe słowo zostało dodane do próbki (wstawienie), albo słowo nie zostało w ogóle przepisane (usunięcie). Dla przykładu, najlepiej działający model dla rozpoznawania mowy angielskiej ma WER równy 0.019, co oznacza, że około 2% słów w zdaniu może mieć błąd w transkrypcji. Wskaźnik WER może być również przedstawiony jako wartość procentowa, gdzie WER równy 1 jest równy 100%. Im mniejszy jest WER, tym lepiej.
Istnieje kilka innych metryk podobnych do WER, takich jak współczynnik błędów znaków (CER) lub współczynnik błędów zdań (SER), ale my zdecydowaliśmy się użyć współczynnika błędów słów jako naszej głównej metryki, ze względu na fakt, że jest to najbardziej powszechna metryka, używana w wielu pracach badawczych dotyczących automatycznego rozpoznawania mowy.
Trening modelu
Modelem użytym w naszym programie do automatycznego rozpoznawania mowy arabskiej jest DeepSpeech2 - rekurencyjna sieć neuronowa, wytrenowana do pobierania spektrogramów mowy i generowania transkrypcji. Przetwarzanie wstępne jest już zaimplementowane w Mozilla DeepSpeech, dlatego nie musieliśmy tworzyć własnej warstwy przetwarzającej. Kolejnym krokiem było przygotowanie danych do treningu - w zbiorze Common Voice znajdują się już pliki .tsv z transkrypcjami, które musimy przekonwertować na pliki rozdzielone przecinkami (.csv), aby DeepSpeech mógł je przetworzyć. Dane zostały podzielone na zbiory treningowe, testowe i walidacyjne w proporcji 50%/25%/25% oryginalnego zbioru danych.
Ze względu na mały zbiór danych, zdecydowaliśmy się na transfer learning - model angielski stał się bazą do treningu arabskiego modelu mowy-tekstu. 3 górne warstwy zostały przetrenowane, a pozostałe warstwy zachowały początkowe wartości wag. Model Deep Speech był trenowany aż do zbieżności - gdy zaczynał się overfitting, trening był przerywany. Wytrenowany model osiągnął WER na poziomie 34%, co oznacza, że mniej więcej jedna trzecia transkrybowanych słów ma błąd - całkiem sporo, ale biorąc pod uwagę ograniczony rozmiar zbioru danych, mogło być znacznie gorzej. W porównaniu z modelem angielskim, dokładność jest prawie 5 razy niższa, ze względu na posiadanie tylko 49 godzin próbek, w porównaniu do tysięcy użytych do treningu modelu angielskiego. Porównanie to można zobaczyć na poniższym histogramie:
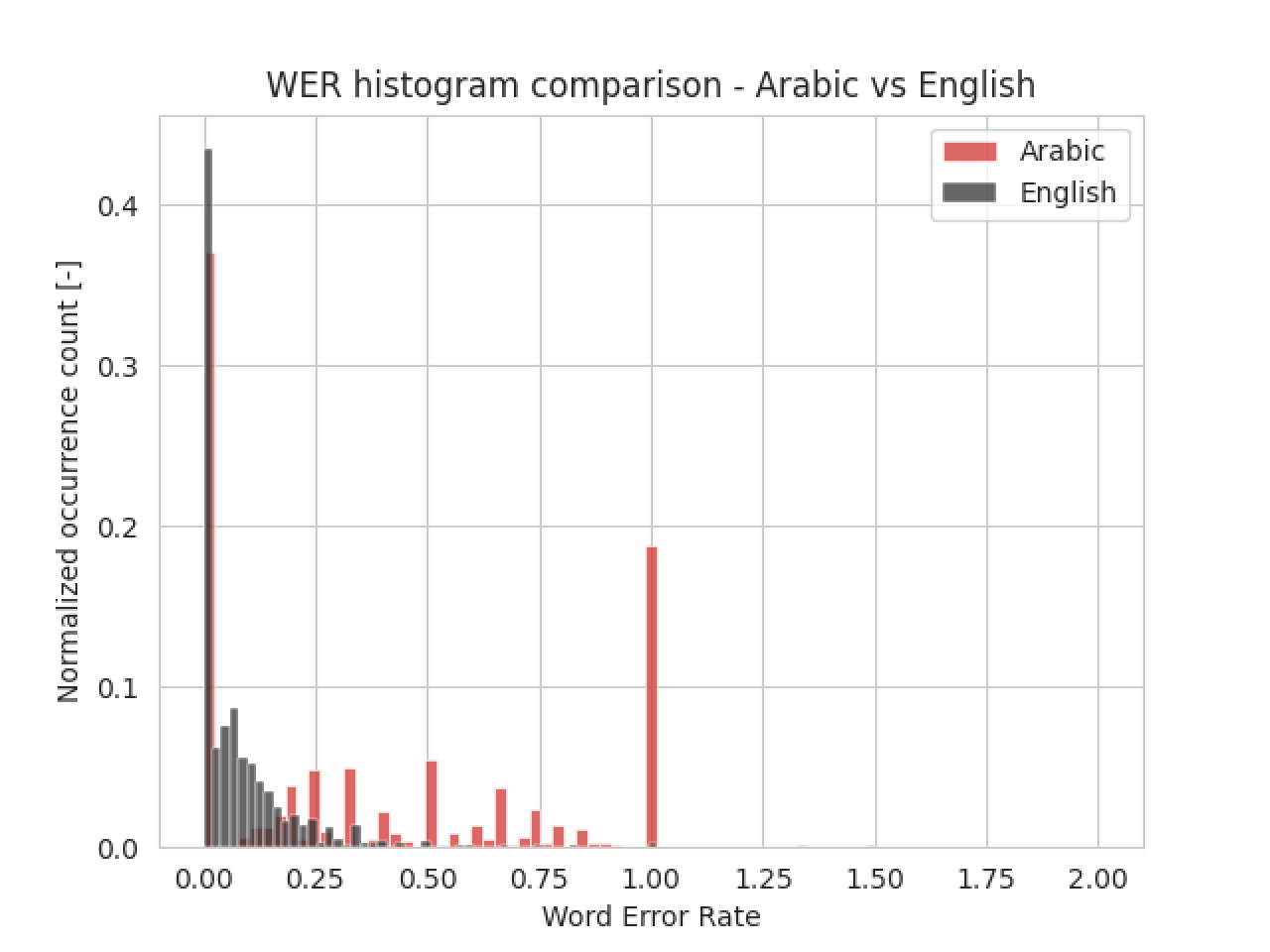
Widać wyraźnie, że trenowanie modelu na 49 godzinach próbek głosu jest nieefektywne - nie ma wystarczającej ilości danych, na których model mógłby trenować, nawet dla uczenia transferowego.
Model językowy - zwiększanie dokładności
Kolejną zaletą DeepSpeecha jest możliwość wykorzystania dodatkowego modelu językowego, zwanego scorerem, do weryfikacji transkrypcji - możemy stworzyć model tekstowy z korpusu tekstowego i użyć go jako sprawdzacza pisowni: ponieważ model językowy jest w stanie poprawić gramatykę, wyjście modelu transkrypcyjnego może zostać zweryfikowane i poprawione, jeśli zajdzie taka potrzeba. Model językowy musi być stworzony przy użyciu KenLM - zewnętrznej biblioteki do tworzenia modeli językowych.
Najlepiej działający model dla rozpoznawania mowy angielskiej ma WER równy 0.019, co oznacza, że około 2% słów w zdaniu może mieć błąd w transkrypcji. Wskaźnik WER może być również przedstawiony jako wartość procentowa, gdzie WER równy 1 jest równy 100%. Im mniejszy jest WER, tym lepiej.
Chociaż użycie scorera nie ma znaczenia przy trenowaniu modelu transkrypcji szerokiego leksykalnie słownika, opłaca się go używać tylko wtedy, gdy próbujemy rozpoznać niewielki podzbiór słów lub gdy nasz zbiór danych jest wystarczająco duży, wtedy model językowy dostraja wyjście modelu transkrypcji. W naszym systemie zastosowanie zewnętrznego modelu językowego pozwoliło na zmniejszenie WER z 37% do 34% - nie jest to wynik spektakularny, ale zwiększyło to dokładność modelu.
Podsumowanie
W tym artykule pokazaliśmy, jak wytrenować model DeepSpeech do transkrypcji próbek głosu oraz jak poprawić dokładność modelu za pomocą zewnętrznego modelu językowego. Oczywiście, jest jeszcze wiele do poprawienia - możemy spróbować użyć innej architektury modelu niż DeepSpeech lub spróbować dostroić nasz obecny model. ASR to rozległy temat, ciągle ewoluujący - zarówno pod względem zastosowań, jak i jakości rozwiązań.


