


W tym wpisie zastanowimy się, czy komputer może pomóc nam w wykrywaniu emocji zawartych w tekście. Czytając artykuły w łatwy sposób możemy wyciągnąć jego statystykę: ilość wystąpień słów czy średnią długość zdania. Zastanówmy się czy moglibyśmy wykorzystać analizę danych do zagadnień bardziej złożonych i subtelnych, zarezerwowanych dotychczas dla człowieka. Takim zadaniem jest przypisywanie sentymentu, czyli pozytywnego, neutralnego bądź negatywnego wydźwięku podanemu zdaniu w celu jego kategoryzacji.

Analiza sentymentu jest typowym problemem NLP. Do problemu można podejść w dwojaki sposób. Jednym z nich jest trenowanie modelu machine learningowego na posiadanych danych i testowaniu w celu sprawdzenia jak dobrze radzi sobie z nowymi danymi. Drugim sposobem jest analiza leksykalna zdania.
O ile dla języka angielskiego dostępna jest cała masa gotowych narzędzi, tak język polski można sklasyfikować jako niezbyt światowy. Również pod względem popularności analiza leksykalna ustępuje podejściu machine learning. Postanowiliśmy więc sprawdzić jak takie podejście radzi sobie z zadaniem analizy sentymentu.
Problem przypisania sentymentu do zdania można podzielić na parę faz. Potrzebujemy podzielić artykuły na zdania, a następnie na tokeny, tj. najczęściej pojedyncze słowa. W tym celu dokonaliśmy oczyszczania tekstu z niepotrzebnych znaków specjalnych i skrótowców utrudniających podział tekstu na zdania.
Po podziale artykułów na zdania przyszedł czas na lemmatyzację, czyli sprowadzenie słowa do formy podstawowej, np. dla czasownika jest to bezokolicznik. To pozwoli na znaczne zmniejszenie zbioru słów emocjonalnych o odmianę przez osobę liczbę czy rodzaje. Użyliśmy narzędzia stanfordNLP - rozpoznającego części mowy jak i formę podstawową podanego słowa.
Posiadając zbiór form podstawowych możemy w końcu przypisać im sentyment ze zbioru LOBI, czyli słów i im odpowiadającym emocjom, a następnie przejść do sedna analizy. Używamy narzędzia spacy dla języka polskiego aby dokonać rozbioru zdania na drzewo zależności: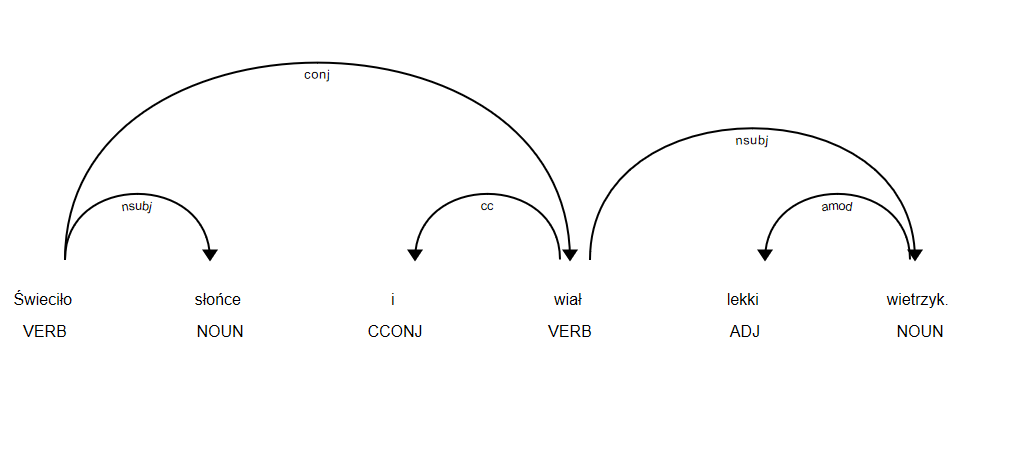
No ale zaraz - zastanówmy się po co w ogóle dokonywać rozkładu zdania - nie wystarczyłoby po prostu zliczyć wystąpień słów pozytywnych i negatywnych i zakwalifikować zdania do odpowiedniej kategorii? Dla prostych zdań podejście to jest zupełnie wystarczające natomiast dla zdań złożonych, takich jak “Kamil pomagał niepełnosprawnym, ale nie zmienia to faktu, że jest złodziejem” wynik byłby daleki od oczekiwanego. W tym celu skomplikowane relacje zdań złożonych podzieliliśmy na części składowe. opisane w zbiorze tagów Universal Dependencies. Każdej ze składowych należało następnie przypisać sentyment pozytywny bądź negatywny. Nic nam jednak ze zbioru luźno powiązanych wartości sentymentu. Aby wiedzieć jak porównywać zdania potrzebujemy ustalić reguły łączenia zdań składowych. Pokażemy teraz przykład jak poradziliśmy sobie ze zdaniem złożonym:
‘Anna miała wielu znajomych, jednak czuła się samotna’
Od razu system podzielił po tagu conj – conjunct zdanie na ‘Anna miała wielu znajomych’ i ‘jednak czuła się samotna’.
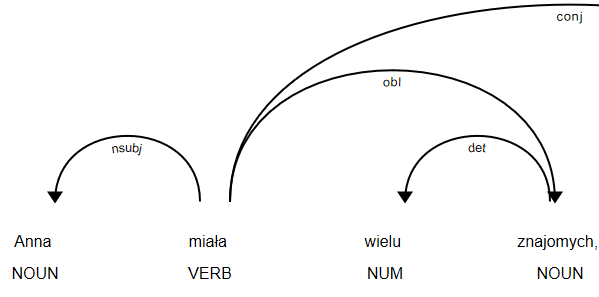
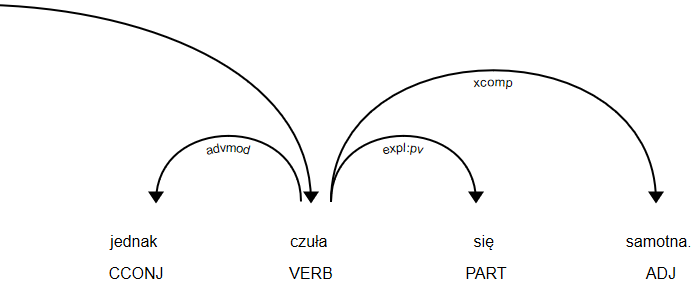
Dla każdego zdania składowego liczona jest oddzielnie wartość sentymentu, z czego pierwsza część jest pozytywna a druga negatywna. Jak w takim wypadku ocenić wydźwięk całego zdania. W tym celu program sprawdza jakim spójnikiem łączą się składowe – w tym wypadku ‘jednak’. W tym wypadku istotniejsza informacja zawarta jest po spójniku, stąd ostatecznie zdanie zostało skategoryzowane jako negatywne.
Na marginesie pragniemy dodać, że reguły nie będą pasować do każdego możliwego zdania. Jeśli podjęlibyśmy się znacznego rozbudowania reguł, bardzo wzrosłaby złożoność algorytmu i czas wykonywania skryptu, co przy 10 zdaniach nie jest kluczowe, natomiast przy dużych zbiorach może znacznie utrudnić analizę.
W końcu przetestowaliśmy działanie na większym zbiorze danych. Zebraliśmy próbkę zdań złożonych o różnym wydźwięku – pozytywnym, neutralnym, negatywnym a także mieszanym, pochodzące z różnych źródeł jak książki, wypowiedzi polityków czy opinie internetowe. Przypisaliśmy im sentyment ocenionego przez program – wartość przewidywaną jak i przez człowieka – wartość rzeczywistą.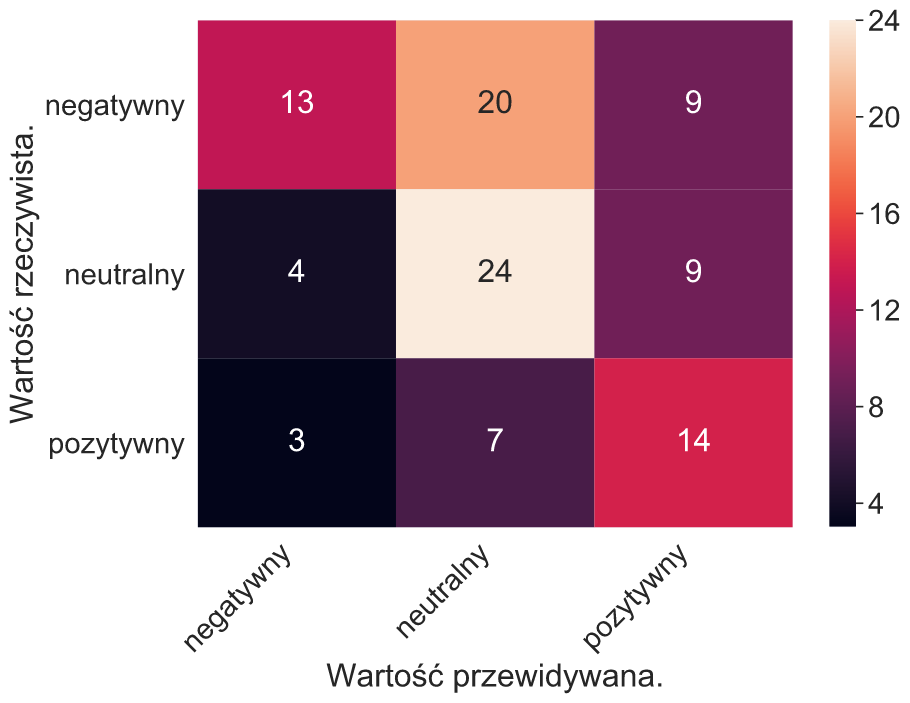
Częsty błąd w ocenia zdania negatywnego może być spowodowany niezrównoważonym zbiorem słów. Dla niedostatecznie rozbudowanego słownictwa o negatywnym wydźwięku program może błędnie klasyfikować zdanie. Ostatecznie warto zastanowić się nad przypadkami które mogą być zupełnie źle zinterpretowane przez system. Przykładowo w zdaniu „Kamil jest miły, ale Artur robi złe rzeczy.” ciężko mówić o jednej wartości dla tego wyrażenia. Sumaryczny wydźwięk, jak i przypisanie wag częściom zdań nie posiada większego sensu – w tym przypadku mamy do czynienia z dwoma wartościami które należałoby traktować oddzielnie.
Podsumowanie
Przedstawiona powyżej analiza ukazuje kolejne kroki, jakie należy podjąć w celu systematyzacji emocji zawartych w tekście. Począwszy od czyszczenia tekstu i przygotowania pod rozkład leksykalny, poprzez lemmatyzację aż do klasyfikacji reguł i niuansów w jaki sposób złożone wypowiedzi można podzielić na prostsze składowe. Warto nadmienić, że dobrze zrównoważony zbiór słów i ich sentymentów, pozwoliłby na znaczne ulepszenie skuteczności algorytmu. Należy też pamiętać, że powyższa metoda jest jedną z wielu możliwych i nie wyczerpuje w całości zagadnienia.


