


AI? ML? Big data? Data Science? Data engineering? O co chodzi? Jakie są różnice? Czy to kolejne buzzwordy? W tym artykule postaramy się rozwiać wątpliwości.
Sztuczna inteligencja (AI – artificial intelligence) w ciągu ostatnich kilku lat przeszła z książek i filmów sci-fi do codzienności. Ot, kolejny raz pomogła odkryć nowy lek, wygrała w kolejną grę z mistrzem świata, a konkurencyjna firma ma wprowadzić produkt z jej wykorzystaniem już za kilka miesięcy. Demitologizując to pojęcie i abstrahując od filozoficznych i futurystycznych rozważań, to co dzisiaj znamy pod pojęciem AI to specjalne algorytmy, które potrafią wnioskować na podstawie przedstawianych im danych.
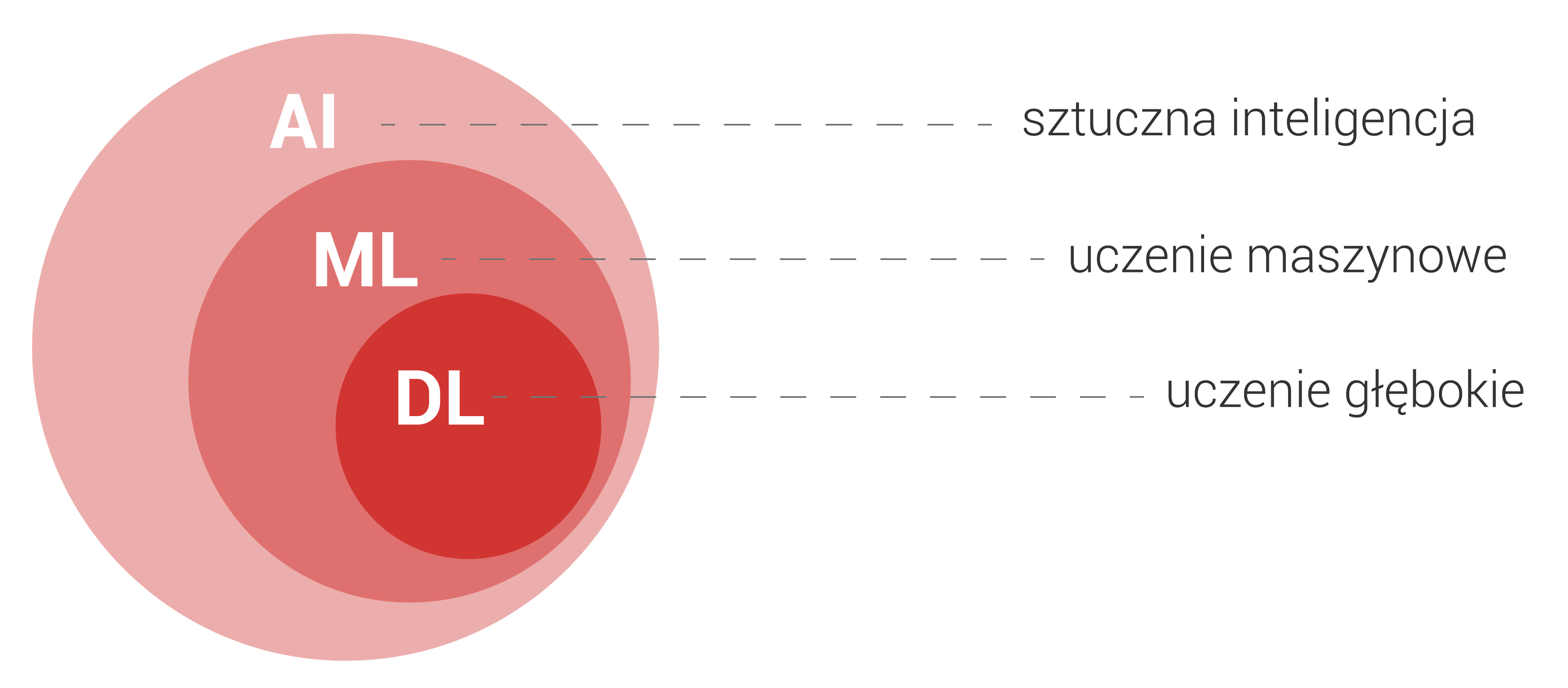
W chwili obecnej największe triumfy, z uwagi na swoją dokładność i możliwości święcą metody tak zwanego uczenia maszynowego (ML – machine learning) i w zasadzie terminy ML i AI dzisiaj stały się synonimami. Powstało, popularne w kręgu inżynierów, powiedzenie mówiące, że AI to termin sprzedażowy, a ML technologiczny: „jeśli coś jest na prezentacji w Powerpoint to jest to AI, jeśli jest napisanie w Pythonie [język programowania] to jest to uczenie maszynowe.”
Pośród algorytmów uczenia maszynowego najbardziej znane są sztuczne sieci neuronowe, a w szczególności te określane jako sieci głębokie (deep learning). Tak jak pozostałe modele uczenia maszynowego, sieci mają więcej wspólnego ze znanymi ze szkoły funkcjami i regresją liniową niż mózgiem i świadomością. Nazwa historycznie nawiązuje do tego, że ich schemat obliczeń był wzorowany na tym jak neurony przewodzą impulsy elektryczne. Sieci przeważnie zorganizowane są w warstwy, które po kolei przetwarzają wejściową informację, aby na końcu zaprezentować wynik. O tym czy sieć jest głęboka czy nie, świadczy ilość tych warstw. Nie ma jednej konkretnej liczby granicznej, ale o sieciach głębokich możemy mówić już przy 5 do 10 warstw. Dla porównania popularne sieci, takie jak VGG16 mają w okolicy 100 warstw.
Dlaczego sieci głębokie i związane z nimi uczenie głębokie są takie wyjątkowe?
Dokonały przełomu. To właśnie one umożliwiają rozpoznawanie obrazów, osób na wideo, automatyczne tłumaczenie tekstów, syntezę mowy czy generowanie fake newsów. Dlaczego te technologie rozwinęły się dopiero teraz? Miały na to wpływ dwa wydarzenia. Po pierwsze uczenie takich sieci wymaga dużej mocy obliczeniowej. Obecnie jest ona stosunkowo tania i łatwo dostępna. Drugi problem to sam mechanizm uczenia. Nie wchodząc w szczegóły techniczne, metody które radziły sobie z uczeniem neuronów zgrupowanych w kilku warstwach miały ogromne problemy z uczeniem neuronów zgrupowanych w kilkadziesiąt i więcej warstw.
Podobno najlepszą definicją big data jest moment, w którym Excel przestaje wystarczać do przetwarzania danych. Ostatnie kilkanaście lat to wystrzał ilości produkowanych informacji, głównie ze względu na postępującą cyfryzację. Analityka na stronie internetowej, czujniki w fabryce, systemy zamówień czy aplikacje w smartfonie zbierają duże ilości danych o klientach lub firmie. W pewnym momencie klasyczne bazy danych nie wystarczają, aby sprawnie je przechowywać. Tutaj pojawiają się rozwiązania typu big data. Nie tylko pozwalają je magazynować, ale również procesować (na przykład w czasie rzeczywistym sprawdzać czy nie wystąpiły niebezpieczne anomalie zarejestrowane przez sensory), udostępniać na przykład na potrzeby generowania raportów, zbierać i przesyłać. To, czy w najbliższej przyszłości lub w nowym projekcie potrzebujesz rozwiązań big data, da się stosunkowo prosto ocenić. Rolą data engineera jest właśnie budowanie systemów gromadzenia i pracy z informacjami.
Data science to kolejny powiązany termin. Zajmująca się tą branżą osoba, czyli data scientist łączy w sobie kompetencje programisty, analityka, zna rozwiązania sztucznej inteligencji (chociaż już wiemy, że lepszym określeniem jest uczenie maszynowe) oraz big data, a co najważniejsze potrafi ich użyć tak, aby wyciągnąć z danych użyteczną wiedzę i wnioski dla biznesu. Rozwiązuje zagadnienia, z którymi nie są w stanie poradzić sobie klasyczni analitycy, wyposażeni w skuteczny arkusz kalkulacyjny i metody statystyczne. O ile data scientist jest naturalnym rozwinięciem analityka danych, tak data engineer powstał w wyniku ewolucji inżyniera baz danych w środowisku big data. Jest to po prostu osoba, która ma za zadanie opracować, a następnie utrzymać bazy danych i systemy do rozwiązań big data. Przykładem nieco skrajnym może być Facebook, który w ciągu sekundy przetwarza miliony komunikatów, powiadomień czy reakcji. Jednak jeżeli planujesz aplikację, z której mają korzystać tysiące osób czy opomiarowane fabryki za pomocą sensorów IoT, musisz rozważyć czy nie potrzebujesz data engineera.
Najlepszą definicją big data jest moment, w którym Excel przestaje wystarczać do przetwarzania danych. Ostatnie kilkanaście lat to wystrzał ilości produkowanych informacji, głównie ze względu na postępującą cyfryzację. Analityka na stronie internetowej, czujniki w fabryce, systemy zamówień czy aplikacje w smartfonie zbierają duże ilości danych o klientach lub firmie. W pewnym momencie klasyczne bazy danych nie wystarczają, aby sprawnie je przechowywać.
Mam nadzieję, że ten krótki post nieco rozjaśnił tytułowe pojęcia. Przede wszystkim warto zapamiętać, że ML to w praktyce techniczny synonim do marketingowego AI, które nie ma nic wspólnego ze świadomością maszyn. Pod hasłem big data kryją się rozwiązania dedykowane danym, których nie da się sprawnie obsługiwać za pomocą klasycznych baz danych, a data scientist i data engineer to zawody będące następstwem ewolucji analityka danych i bazodanowca w świecie pełnym danych, do których obsługi i analizowania trzeba szerszej gamy narzędzi i umiejętności niż kiedyś.


